נספחים

תוכן העניינים
הוראות המופיעות בגוף של מבנה while ומתבצעות כל עוד תנאי הלולאה מתקיים צריכות להיות מוזזות ימינה ביחס לשורה הראשונה במבנה. הקוד התקין:
age = input(‘Insert age; -1 to stop: ‘)
while age != ‘-1’:
print(age)
age = input(‘Insert age; -1 to stop: ‘)
נספח א' – פרישֹת מחרוזת על יותר משורה אחת
בכתיבת ערך מסוג מחרוזת נוכל לפרוש אותו על פני יותר משורה אחת. נעשה זאת באמצעות הוספת לוכסן שמאלי במקומות שהמחרוזת צריכה לרדת בהם שורה. דוגמה:
s1 = ‘first line \
second line \
third line’
על אף שהמחרוזת נכתבה כאן בשלוש שורות, מבחינת פייתון היא מחרוזת אחת: מחרוזת זו מתחילה בעשרת התווים first line (כלומר התו ‘f’, התו ‘i’, וכו’), ממשיכה בכמה רווחים (אלו הבאים בתחילת השורה השנייה של ההוראה), ממשיכה באחד עשר התווים second line, ממשיכה בכמה רווחים נוספים (אלו הבאים בתחילת השורה השלישית של ההוראה), ומסתיימת בעשרת התווים third line. נוכל להיווכח שפייתון רואה במחרוזת s1 מחרוזת אחת אם נדפיס אותה ב-shell כך.
>>> s1
first line second line third line
וגם אם נדפיס את המחרוזת s1 באמצעות הפונקציה print:
print(s1)
>>>
first line second line third line
דרך אחרת לפרוש מחרוזת על פני כמה שורות היא לתחום את המחרוזת משני צדיה לא בגרש ולא במירכאות אלא בשלושה סימני גרש או בשלושה סימני מירכאות. דוגמה:
s2 = “””first line
second line
third line”””
בשיטה זו הפרישה על כמה שורות אינה רק אופן של כתיבה אלא הגדרה מפורשת של ירידת שורה בתוך המחרוזת. גם הפעם נוכל לבדוק זאת באמצעות הדפסת המחרוזת ב-shell:
>>> s2
‘first line \n second line \n third line’
בתוך המחרוזת מופיע פעמיים הצירוף \n , צירוף תווים שלא אנו כתבנו. כפי שנראה בפרק הששי, המחרוזת ‘\n’ מסמנת ירידת שורה, והדפסתה גורמת לירידת שורה. נדפיס למשל את המחרוזת s2 באמצעות הפונקציה print:
print(s2)
>>>
first line
second line
third line
לאחר שהודפסה תחילת המחרוזת, ‘first line’, הודפס הצירוף ‘\n’ והדפסתו התבטאה בירידת שורה. כך קרה גם בהדפסת תת המחרוזת ‘\n’ השנייה המופיעה במחרוזת שיש במשתנה s2.
נספח ב' - האופרטור =+
פעולה שכיחה בתכניות מחשב היא הוספת ערך מסוג אחד לערך מסוג שווה המוצב במשתנה. דוגמה:
x = 1
x = x + 5
print(x)
>>>
6
הוראות מעין זו אפשר לקצר באמצעות האופרטור += ולכתוב כך:
x = 1
x += 5
print(x)
>>>
6
ההוראה השנייה בקוד זה פירושה: יש להוסיף 5 למספר שיש במשתנה x ולשים את התוצאה במשתנה x.
לפעמים אפשר להשתמש באופרטור += לקיצור הוראות המוסיפות משתנה למשתנה. דוגמה: את הקוד הזה –
x = 6
y = 1
x = x + y
print(x)
>>>
7
אפשר לכתוב בקיצור כך:
x = 6
y = 1
x += y
print(x)
>>>
7
ההוראה השלישית בקוד זה מוסיפה את המספר שיש במשתנה y למספר שיש במשתנה x ושמה את התוצאה במשתנה x.
שתי הדוגמות האחרונות חיברו מספר למספר, ובשתיהן תוצאת החיבור לא השתנתה כשהחלפנו שימוש באופרטור + בשימוש באופרטור += .
כפי שמוסבר בפרק החמשי (סעיף 7), אפשר להשתמש באופרטור + גם ברשימות. דוגמה:
lst = [‘a’, ‘b’]
lst = lst + [‘c’, ‘d’]
print(lst)
>>>
[‘a’, ‘b’, ‘c’, ‘d’]
גם כאן, בהוספת רשימה לרשימה, אפשר לקצר את הכתיבה באמצעות שימוש באופרטור += במקום באופרטור + . ספציפית, אפשר לכתוב כך את הפעולה שמבצע הקוד למעלה:
lst = [‘a’, ‘b’]
lst += [‘c’, ‘d’]
עם האמור, יש לתת את הדעת שתוצאת הפעלת האופרטור + על רשימות ותוצאת הפעלת האופרטור += על רשימות אינן זהות לגמרי.
נעיין בקוד הזה:
lst = [‘a’, ‘b’]
lst2 = lst
lst = lst + [‘c’, ‘d’]
print(lst)
print(lst2)
>>>
[‘a’, ‘b’, ‘c’, ‘d’]
[‘a’, ‘b’]
ההוראה הזאת:
lst = [‘a’, ‘b’]
יוצרת אובייקט בזכרון המחזיק רשימה, ושמו הוא lst:

ההוראה הבאה בקטע הקוד:
lst2 = lst
נותנת שם נוסף לאובייקט:
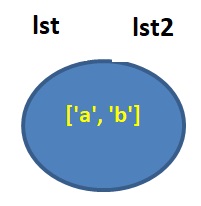
ההוראה השלישית:
lst = lst + [‘c’, ‘d’]
יוצרת אובייקט חדש בזכרון, אובייקט השונה מהאובייקט ששמו היה lst עד לביצוע הפעולה, ומחזיק את הרשימה אחרי התוספת.
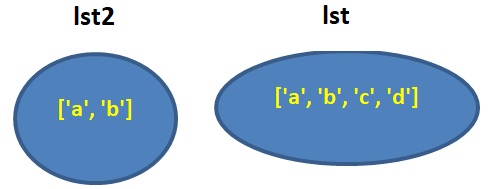
מהלך עניינים אחר יש בקטע קוד זה, ואפשר להבחין בכך כבר בעיון בערכים המודפסים:
lst = [‘a’, ‘b’]
lst2 = lst
lst += [‘c’, ‘d’]
print(lst)
print(lst2)
>>>
[‘a’, ‘b’, ‘c’, ‘d’]
[‘a’, ‘b’, ‘c’, ‘d’]
גם הפעם הקוד מתחיל ביצירת אובייקט בזכרון המחזיק רשימה ושמו הוא lst:
וגם כאן ההוראה השניה נותנת שם נוסף לאובייקט:
ואולם ההוראה השלישית, המשתמשת באופרטור +=
lst += [‘c’, ‘d’]
אינה יוצרת אובייקט חדש בזכרון, אלא מעדכנת את הרשימה באובייקט הקיים!
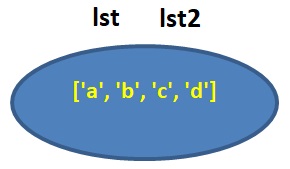
יש לתת את הדעת להבדלים אלה בשימוש באופרטור += ברשימות, וכללית באובייקטים בפייתון. דיון מפורט יותר מזה בהם ובסיבותיהם חורג מגבולותיו של ספר זה.
נספח ג' – עוד על שימוש באינדקסים שליליים
ראינו כי אפשר להשתמש באופרטור [ ] כדי לגשת לערכים ברצפים וכדי לשנותם. בכתיבת הוראות המשתמשות באופרטור נציין בתוך הסוגריים את האינדקסים של הערכים שאנו מבקשים לגשת אליהם או לשנותם. דוגמות:
אנו איננו יודעים להבין את הטקסט המוצג כאן. לעומתנו Word יודעת גם יודעת, והיא ממירה את תוכן הקובץ לטקסט שגם אנו יכולים להבין.
lst = [‘a’, ‘b’, ‘c’]
secondItem = lst[1]
firstAndSecondItems = lst[0:2]
lst[0] = ‘A’
בדוגמות אלו וגם ברוב הדוגמות לשימוש באופרטור [ ] המוצגות בגוף הספר, נעשה שימוש באינדקסים הלקוחים ממערכת האינדקסים החיוביים. בהפעלת האופרטור [ ] על רצפים אפשר להשתמש גם באינדקסים הלקוחים ממערכת האינדקסים השליליים. דוגמות:
lst = [‘a’, ‘b’, ‘c’]
print(lst[-2])
print(lst[-3:-1] )
lst[-2] = ‘A’
print(lst)
>>>
b
[‘a’, ‘b’]
[‘a’, ‘A’, ‘c’]
בהפעלת באופרטור [ ] ליצירת עותק של מקטע רצף, אם המקטע צריך להכיל את הרצף מתחילתו או עד סופו, אפשר לא לציין את גבולות המקטע (ראו פרק רביעי, סעיף 5.9). כך הדבר אם מציינים את הטווח באמצעות אינדקסים חיוביים, וכך גם הדבר אם מציינים אותו באמצעות אינדקסים שליליים. דוגמות:
lst = [‘a’, ‘b’, ‘c’]
print(lst[-2])
print(lst[-3:-1] )
lst[-2] = ‘A’
print(lst)
>>>
b
[‘a’, ‘b’]
[‘a’, ‘A’, ‘c’]
אפשר להשתמש במערכת האינדקסים השליליים גם בהפעלת הפונקציה index. דוגמה:
lst = [‘a’, ‘b’, ‘c’]
ind = lst.index(‘b’, -2)
החיפוש כאן הוא אחר התו ‘b’ ברשימה הזאת:
[‘b’, ‘c’]
ואפשר לתת אינדקסים שליליים גם בתור הארגומנט השני והארגומנט השלישי של הפונקציה index. דוגמה:
lst = [‘a’, ‘b’, ‘c’]
ind = lst.index(‘b’, -2, -1)
print(ind)
>>>
1
כאן החיפוש אחר התו ‘b’ מתחיל בערך הנמצא באינדקס 2- ברשימה lst, וגם מסתיים בערך המופיע באינדקס 2-.
נשוב לאופרטור [ ] ובשימוש בו ליצירת עותק של מקטע רצף: אם נציין את תחילת המקטע באמצעות אינדקס שלילי, ואינדקס זה יהיה קטן מהאינדקס של הערך הראשון ברצף, הרצף המקטע המוחזר יתחיל בערך הראשון ברצף הנתון. דוגמה:
lst = [‘a’, ‘b’, ‘c’]
print(lst[-10:-1])
>>>
[‘a’, ‘b’]
בדוגמה זו האינדקס המציין את תחילת המקטע הוא 10- , אך האינדקס של הערך הראשון ברצף שעליו אנו מפעילים את האופרטור [ ] – כלומר הרשימה lst – הוא 3-. לכן המקטע המוחזר מתחיל בערך הראשון ברשימה.
ובדומה בפונקציה index – אם ניתן לה אינדקס שלילי בתור ארגומנט שני, ואינדקס זה יהיה קטן מהאינדקס של הערך הראשון ברצף, החיפוש יתחיל בערך הראשון ברצף. דוגמה:
lst = [‘a’, ‘b’, ‘c’]
ind = lst.index(‘b’, -10, -1)
בדוגמה זו החיפוש צריך להתחיל בערך של הרשימה lst הנמצא באינדקס 10-. כיוון שאין ערך כזה החיפוש יתחיל בתחילת הרשימה lst.
נספח ד' – פתיחת קובץ באמצעות ההוראה with...as
סגירת קובץ לאחר שנפתח היא פעולה הכרחית, בייחוד כשמטרת הפתיחה היא כתיבה בקובץ. קובץ שנפתח ואינו נסגר עלול להישאר פתוח והיותו במצב זה יכולה לעורר קשיים. הצרה היא שאף אם הוראת הסגירה נכתבת במפורש, עלולים להיווצר מצבים שהיא לא תבוצע. נעיין למשל בקוד הזה:
f = open(‘file.txt’, ‘w’)
salary = float(input(‘Enter your current salary: ‘))
newSalary = salary + 1000
f.write(str(newSalary)
f.close()
ההוראה הראשונה פותחת קובץ לכתיבה. אם המשתמשת הכניסה מחרוזת שאינה מייצגת מספר שלם, כמו למשל המחרוזת ‘nudnikit’, זימון הפונקציה float יוליך לשגיאה. התכנית תיעצר, והוראת הסגירה של הקובץ לא תבוצע.
לאור האמור מתכנתות ומתכנתים מנוסים מעדיפים לפתוח קובץ באמצעות ההוראה with…as. דוגמה:
with open(‘file.txt’, ‘w’) as f:
f.write(‘something’)
salary = float(input(‘Enter your salary: ‘))
newSalary = salary + 1000
f.write(str(newSalary)
פתיחת קובץ באמצעות ההוראה with…as מבטיחה שהקובץ ייסגר אף על פי שלא נכתבה הוראת הסגירה, וגם אם תתרחש שגיאה. שימו לב שהסגירה אינה תלויה בהוראת הכתיבה המופיע בגוף ההוראה with…as – כאן כתיבה של המחרוזת ‘something’ בקובץ.
נוסיף בקצרה כי ההוראה with…as היא כלי חילופי לכלי אחר הקיים בפייתון ונועד לטפל בשגיאות זמן ריצה המוכרות בשם ‘חריגות’ (exceptions), ובהיקרותן לא רק בקבצים כי אם גם באובייקטים מסוגים אחרים. הכלי האחר הוא ההוראה try…finally והוא אינו נידון בספר זה.
הפונקציה ות strip, rstrip ו-lstrip משמשות להפשטת תווים ממחרוזת נתונה.
הפונקציה strip מזומנת באמצעות אובייקט של מחרוזת נתונה, oldS, יוצרת מחרוזת חדשה, newS המבוססת על המחרוזת oldS, ומחזירה את המחרוזת newS. בזימון הפונקציה strip אפשר להעביר אליה ארגומנט מחרוזת chars. התחביר הוא זה:
oldS.strip(chars)
במקרה זה newS היא המחרוזת oldS ללא התווים במחרוזת chars המופיעים בתחילתה ובסופה.
אפשר גם לא להעביר ארגומנטים לפונקציה strip. במקרה זה newS היא המחרוזת oldS ללא תווי רווח המופיעים בתחילתה ובסופה.
דוגמות:
s = ‘*-strip-me-‘
newS = s.strip(‘-*’)
print(newS)
>>>
strip-me
s = ‘ strip me ‘
newS = s.strip()
print(newS)
>>>
strip me
זימון הפונקציה lstrip (קיצור של left strip) ופעולתה דומים לאלה של הפונקציה strip, בהבדל אחד: השמטת התווים – אלה המופיעים בארגומנט chars או תווי רווח – היא רק מתחילת המחרוזת oldS. דוגמות:
s = ‘*-strip-me-‘
newS = s.lstrip(‘-*’)
print(newS)
>>>
strip-me-
s = ‘ strip-me ‘
newS = s.lstrip()
print(newS)
>>>
strip-me-
זימון הפונקציה rstrip (קיצור של right strip) ופעולתה דומים לאלה של הפונקציה strip, בהבדל אחד: השמטת התווים – אלה המופיעים בארגומנט chars או תווי רווח – היא רק מסוף המחרוזת oldS. דוגמות:
s = ‘*-strip-me-‘
newS = s.rstrip(‘-*’)
print(newS)
>>>
*-strip-me
s = ‘ strip-me ‘
newS = s.rstrip()
print(newS)
>>>
strip-me
נספח ו' – רכיסת רצפים: הפונקציה zip
ב’רכיסת רצפים’ כוונתנו ליצירת רשימה מערכים מקבילים (כלומר באינדקסים שווים) בשני רצפים או יותר שכולם שווי גודל. נניח למשל שנתונות שתי רשימות lst1 ו-lst2:
lst1 = [‘Israel’, ‘USA’, ‘France’]
lst2 = [1948, 1776, 1789]
בשתי הרשימות יש שלושה ערכים בדיוק. לרכוס את הרשימות lst1 ו-lst2 פירושו להכין אוסף זה:
(‘Israel’, 1948), (‘USA’, 1776), (‘France’, 1789)
הרכיסה יוצרת מבנה המכיל רשומות פנימיות. מספר הרשומות הפנימיות שווה למספר הערכים שיש בכל אחת משתי הרשימות הנתונות (כאן: 3), ומספר הערכים בכל רשומה שווה למספר הרשימות הנרכסות (כאן: 2). כל רשומה מכילה את הערכים המקבילים ברשימות הנתונות, לפי סדר מסוים (כאן: קודם הערך ברשימה -lst1 ואחר כך הערך ברשימה lst2).
נרכוס רצפים באמצעות הפונקציה zip. קטע קוד זה מדגים כיצד מזומנת פונקציה זו וגם כיצד מודפס תכנו של המבנה שהיא מחזירה:
lst1 = [‘Israel’, ‘USA’, ‘France’]
lst2 = [1948, 1776, 1789]
for item in zip(lst1, lst2):
print(item)
>>>
(‘Israel’, 1948)
(‘USA’, 1776)
(‘France’, 1789)
בדומה למספרים במבנה שיוצרת range (ראו פרק רביעי, סעיף 6.2), גם לרשומות במבנה שיוצרת zip אי אפשר לגשת ישירות, כלומר באמצעות האופרטור [ ], אלא בעקיפין, באמצעות סריקתן בלולאת for. אמנם אפשר להמיר את המבנה שיוצרת הפונקציה zip לרשימה באמצעות הפונקציה list – כך נוכל להפעיל עליו פעולות ברשימות. דוגמה:
lst1 = [‘Israel’, ‘USA’, ‘France’]
lst2 = [1948, 1776, 1789]
lst = list(zip(lst1, lst2))
print(lst)
>>>
[(‘Israel’, 1948), (‘USA’, 1776), (‘France’, 1789)]
ככלל הפונקציה zip פותרת בעיה זו: נתונים n רצפים – כגון רשימות, מחרוזות ורשומות. כל הרצפים שווי גודל. יש ליצור מהם רשימה המכילה n רשומות; כל רשומה פנימית מכילה את כל הערכים המקבילים (כלומר באינדקס שווה) ב-n הרצפים, לפי הסדר שקיבלה אותם הפונקציה zip. הנה דוגמה לפעולת zip על שני רצפים מסוג אחר – מחרוזת:
openingPar = ‘([{‘
closingPar = ‘)]}’
for pair in zip(openingPar, closingPar):
print(pair)
>>>
(‘(‘, ‘)’)
(‘[‘, ‘]’)
(‘{‘, ‘}’)
בלולאת for הסורקת מבנה שיוצרת zip אפשר להשתמש בהשמה מרובה (ראו פרק שמיני, סעיף 7). דוגמה:
lst1 = [‘Israel’, ‘USA’, ‘France’]
lst2 = [1948, 1776, 1789]
for country, year in zip(lst1, lst2):
print(country, year)
>>>
Israel 1948
USA 1776
France 1789
כאן כל רשומה שהלולאה סורקת מפורקת לשני משתנים: country ו-year, בסדר זה. גוף הלולאה משתמש בערכים הנשמרים במשתנים אלה.
נספח ז' – משתנים גלובליים
פונקציה יכולה לשנות את ערכם של משתנים המוגדרים מחוץ לה ומחוץ לפונקציות אחרות. הדבר נעשה באמצעות הגדרת משתנה בתוך הפונקציה בתור משתנה גלובלי באמצעות המילה השמורה global. שם המשתנה זהה לשם המשתנה המוגדר מחוץ לפונקציה. דוגמה:
def computeGrade(factor = 5):
global userGrade
userGrade = userGrade + factor
userGrade = 85
computeGrade()
print(userGrade)
>>>
90
הקוד מתחיל ביצירת המשתנה userGrade ואתחולו למספר 85. אחר כך הפונקציה מזומנת בלי ארגומנטים. הפונקציה computeGrades מגדירה משתנה בשם userGrade בתור משתנה גלובלי וכך יכולה לשנות את הערך של המשתנה userGrade שהוגדר מחוץ לה. היא מוסיפה לערך במשתנה הזה את ערך ברירת המחדל של הפרמטר factor. כפי שאפשר לראות לשינוי הזה יש ביטוי גם מחוץ לפונקציה: בהדפסת הערך userGrade מתקבל הפלט 90.
הגדרת משתנים גלובליים עלולה ליצור תכנית שקשה להבינה וקשה לנפות שגיאות בה. לכן כדאי לא להשתמש בהם אם הדבר אפשרי (בייחוד באמצעות שימוש בהוראה return ובערכי החזרה), ואם משתמשים בהם – לעשות זאת בתכניות קטנות. ככלל יש לשאוף ליצור פונקציות שאין להן השפעות נלוות על נתונים הנשמרים מחוץ להן.
נספח ח' – עוד על אמת ושקר בפייתון
בפייתון הערך True שקול לערך 1:
print(True == 1)
>>>
True
ובפייתון הערך False שקול לערך 0:
print(False == 0) >>> True
אחת ההשלכות של השקילויות הללו היא שבהקשרים מתאימים הערכים True ו-False נחשבים למספרים שלמים וגם אפשר להמירם למספרים שלמים במפורש. דוגמות:
print(isinstance(True, int))
>>>
True
print(int(False))
>>>
0
לאור האמור, והואיל והמספרים 0 ו-1 הם ערכים שמוגדר ביניהם יחס של השוואה, יוצא שאפשר למיין רצפים של ערכים בוליאניים. דוגמה:
lst = [True, False, True, False, True]
lst.sort()
print(lst)
>>>
[False, False, True, True, True]
גם אפשר להשתמש ב-True ו-False בביטויים שמשמשים בהם המספרים 0 ו-1. בין השאר אפשר להשתמש בערכים בוליאניים ליצירת עותקים של ערכים ברצפים באמצעות האופרטור [ ]:
lst = [7, 2]
print(lst[False])
print(lst[True])
>>>
7
2
זאת ועוד: בפייתון המשמעות “אמת” אינה שמורה בלעדית לערך הבוליאני True, והמשמעות “שקר” אינה שמורה בלעדית לערך הבוליאני False. ככלל כל אובייקט בשפה שהוא מספר הוא “אמת” אלא אם כן הוא 0, וכל אובייקט שאינו מספר הוא “אמת” אלא אם כן הוא ריק (נדגיש: אין הכוונה כאן לזהות לערכים הבוליאניים True ו-False אלא למשמעות “אמת” ו”שקר”). כך למשל בנוגע לשני האובייקטים שיוצרות הוראות השמה אלו:
num = 5
s = ‘something’
המספר 5 והמחרוזת ‘something’ אינם זהים לערך True, אך מבחינת פייתון משמעותם היא “אמת”. ביטוי אחד לדברים הוא בהוראת if. התבוננו בקוד הזה:
if s:
print(‘something is true’)
>>>
something is true
לכתוב מחרוזת במקום התנאי הנבדק בהוראת if פירושו לבדוק האם המשמעות של המחרוזת היא אמת או שקר. כאמור משמעותה של מחרוזת נחשבת אמת אם היא אינה ריקה. ולכן כאן מתבצעת הוראת ההדפסה.
דוגמה נוספת:
if not 5:
print(‘meaning: false’)
else:
print(‘meaning: true’)
>>>
meaning: true
בהקשר של הביטוי שהערך 5 מופיע בו כאן, משמעותו של הערך הזה היא “אמת”. הואיל וכך משמעותו של הביטוי not 5 היא “שקר”, וזו הסיבה שהוראה בחלק ה-else היא המתבצעת.
באמצעות הפונקציה bool אפשר לקבל מפורשות את הערך הבוליאני המתאים לאובייקט בפייתון. נעביר אליה את האובייקט והיא תחזיר ערך בוליאני שמשמעותו זהה למשמעות הבוליאנית של האובייקט. דוגמה:
lst = []
print(bool(lst))
>>>
False
משמעותה של רשימה ריקה היא “שקר”. הפונקציה bool תחזיר את הערך הבוליאני שזו גם משמעותו.