פרק אחד עשר
טיפול בגליונות נתונים - מבט על pandas

תוכן העניינים
(4) טעינת קובץ נתונים ל-DataFrame
(7) סוגי ערכים בעמודות DataFrame
(10) יצירת עותקים של מקטעי DataFrame
(12) השמת ערך בתא, הוספת עמודות ועדכונן
(16) חישובים מתמטיים וסטטיסטיים
(17.1) יצירת DataFrame ממילון ויצירת מילון מ-DataFrame
(17.6) הפעלת פעולות במחרוזות על ערכים בעמודה
הוראות המופיעות בגוף של מבנה while ומתבצעות כל עוד תנאי הלולאה מתקיים צריכות להיות מוזזות ימינה ביחס לשורה הראשונה במבנה. הקוד התקין:
age = input(‘Insert age; -1 to stop: ‘)
while age != ‘-1’:
print(age)
age = input(‘Insert age; -1 to stop: ‘)
(1) מבוא
גליונות נתונים (Datasheets) הם מקור קלט חשוב ורווח לתכניות מחשב, ותכניות מחשב המטפלות בגליונות נתונים מבצעות בהם מגוון פעולות, כגון קבלת תצפית (שורה) לפי ערך במשתנה (בעמודה), קבלת ערך במשתנה אחד לפי ערך במשתנה אחר, וקבלת רשימת ערכים במשתנה אחד לפי ערך במשתנה אחר. נוסף על פעולות אלה עשויות תכניות מחשב המטפלות בגליונות נתונים להדפיס את הנתונים בגליונות, למיינם, לסננם, ועוד ועוד. בכתיבת תכניות כאלו נוכל לכתוב בעצמנו את הקוד המטפל בגליון הנתונים. לחילופין נוכל להשתמש בחבילה של פייתון, pandas שמה. חבילה זו כוללת מגוון פונקציות ייעודיות המבצעות שלל פעולות בגליונות נתונים. תכליתו של פרק זה היא לסקור את pandas ובייחוד פעולות עיקריות במבנה נתונים אחד המוגדר בה: DataFrame. הסקירה אינה ממצה, ועם זאת מעמידה יסודות מוצקים למחקר נוסף של רכיבי החבילה. היא מועילה בייחוד למי שקוראים בה במקביל לכתיבת תכנית המטפלת בגליונות נתונים ועושים את צעדיהם הראשונים בשימוש ב-pandas. למעיינים אלה כדאי לקרוא בשלב ראשון את סעיפי הפרק הראשונים, ואחר כך לדלג לסעיפים העוסקים בפעולות הדרושות להם. בסוף הפרק מוצגת דוגמה מעשית לכתיבת תכנית המשתמשת במקצת הפעולות המוצגות בו.
(2) מהי pandas?
pandas (קיצור של panel data) היא חבילה של פייתון. היא נועדה לשמש בביצוע פעולות מגוונות בגליונות נתונים, כגון שמירתם, עיבוד הנתונים בהם והדפסתם, טיפול בערכים חסרים ועוד, כל זאת ביעילות ובאמינות. DataFrame הוא מבנה נתונים המשמש ב-pandas לשמירת אוספים דו-ממדיים, כלומר טבלאות, והוא אחד מכמה מבני נתונים המוּבְנים בחבילה. לשמירת נתונים בעמודה אחת של DataFrame או בשורה אחת שלה משמש בחבילה מבנה נתונים אחר: Series; כפי שנראה להלן, בהקשרים מסוימים אפשר להשתמש בו בדומה לשימוש ברשימה (list). לשמירת אוסף של טבלאות מסוג DataFrame משמש בחבילה מבנה נתונים שלישי: Panel. כאן נעסוק בעיקר ב-DataFrame.
ראוי לתת את הדעת כי מבני הנתונים המוגדרים ב-pandas והפונקציות הנכללות בה מבוססים על כמה חבילות וספריות אחרות. שימוש ב-pandas מחייב לעתים היכרות עם חבילות וספריות אלו, ובייחוד עם אחת מהן: numpy, ספרייה חשובה שייעודה העיקרי הוא ביצוע חישובים מתמטיים וסטטיסטיים. עם זאת אפשר לבצע פעולות רבות ב-pandas בלי צורך להבין את הנעשה “מאחורי הקלעים” באמצעות פונקציות מ-numpy ומספריות אחריות ש-pandas מיוסדת עליהן.
כדי להשתמש ב-pandas חובה לייבא אותה במפורש לתכנית. נהוג לכתוב את הוראת הייבוא כך:
import pandas as pd
הוראה זו מגדירה אובייקט pandas בשם pd והוא משמש בגישה לפונקציות של החבילה. הייבוא עצמו מחייב ש-pandas תהיה מותקנת בסביבת הפיתוח.
(3) הנתונים המשמשים בדוגמות
הדוגמות לשימוש ב-pandas ובייחוד הדוגמות לטיפול ב-DataFrame שיובאו להלן מבוססות על נתונים שמוצאם בגליון השומר מידע בנוגע לשכיחויות של מילים במספר ספרים. כל תצפית בגליון מתעדת נתונים בנוגע למילה אחת בספר אחד. המשתנים בגליון הם אלה:
• FILENAME – שם הקובץ המכיל את הטקסט של הספר שהמילה מופיעה בו (ללא הסיומת .txt): text1, text2, text3 וכן הלאה
• WORD – המילה
• FREQ – שכיחות המילה בקובץ
בגליון אין כפילויות בשורות, כלומר אין שתי תצפיות המתעדות שכיחות של מילה אחת בקובץ אחד.
לצורך הדוגמות נשתמש בגרסה מוקטנת של גליון הנתונים. גרסה זו שמורה בקובץ freq.csv (לחצו על שמו כדי להורידו). היא מכילה 11 תצפיות בלבד. הנה כך היא נראית כאשר הקובץ freq.csv נפתח ב”אקסל”:
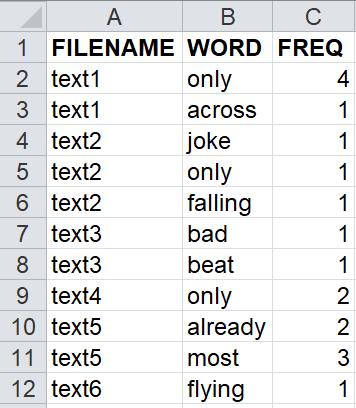
להלן נראה כיצד לשמור את הנתונים המופיעים בטבלה זו בתוך DataFrame. הנה כך תראה ה-DataFrame כשתודפס:
FILENAME WORD FREQ
0 text1 only 4
1 text1 across 1
2 text2 joke 1
3 text2 only 1
4 text2 falling 1
5 text3 bad 1
6 text3 beat 1
7 text4 only 2
8 text5 already 2
9 text5 most 3
10 text6 flying 1
כפי שאפשר לראות, לכל שורה ב-DataFrame חוץ משורת הכותרת יש אינדקס. עמודת האינדקסים המוצגת כאן אינה חלק מהטבלה עצמה.
(4) טעינת קובץ נתונים ל-DataFrame
כדי לשמור ב-DataFrame נתונים מקובץ csv נשתמש בפונקציה read_csv:
df = pd.read_csv(‘freq.csv’)
הפונקציה read_csv מקבלת שם של קובץ. היא מחפשת אותו בתיקיה שהוגדרה בתור תיקיית העבודה (working directory; למשל באמצעות הפונקציה (os.chdir(). אם היא מוצאת את הקובץ בתיקיה זו היא טוענת את הנתונים בו לתוך DataFrame ומחזירה אובייקט המחזיק את ה-DataFrame הזאת. כאן ניתן לו השם df. נשתמש באובייקט df כדי לגשת לנתונים ב-DataFrame וכדי לבצע פעולות עליהם. הזימונים של פונקציות הפועלות על אובייקט זה יכתבו בתבנית מסוימת, כדלקמן:
df.funcName(. . . )
גישה לתכונות או למשתנים של האוביקט df נעשית בתבנית זו:
df.attribute
נשוב לפונקציה read_csv: אם הערכים בקובץ csv ששמו ניתן לפונקציה זו מופרדים זה מזה בתו שאינו פסיק, יש לציין זאת במפורש בזימון הפונקציה. הדבר נעשה באמצעות מתן ארגומנט מתאים לפרמטר של הפונקציה ששמו sep (קיצור המילה separator). אם למשל ההפרדה נעשית באמצעות התו טאב, נכתוב כך:
df = pd.read_csv(‘freq.csv’, sep = ‘\t’)
כאן נתנו לפרמטר sep את התו ‘\t’, וכך ציינו שבקובץ freqTabs.csv הערכים בכל שורה מופרדים זה מזה באמצעות התו טאב.
נעיר כי אפשר ליצור DataFrame גם על יסוד קובץ “אקסל”. הדבר נעשה באמצעות הפונקציה read_excel. דוגמה:
df = pd.read_excel(‘freq.xlsx’)
טעינת הנתונים בקובץ “אקסל” ל-DataFrame והטיפול בהם צריכים לתת את הדעת שהקובץ עשוי להכיל כמה גליונות. בנוסף לעתים יש צורך לציין במפורש את המכניזם שבאמצעותו יחולק הקובץ למילים. הדבר נעשה באמצעות מתן ארגומנט לפרמטר engine. פרמטר זה מקבל את המחרוזת ‘c’ או ‘python’. דוגמה:
df = pd.read_csv(“freq.csv”, engine = “python”)
(5) כתיבת DataFrame בקובץ
נשמור DataFrame בקובץ csv באמצעות הפונקציה to_csv , כך:
df.to_csv(‘newFreq.csv’)
שם הקובץ החדש הוא newFreq.csv. ברירת המחדל היא שהערכים בשורות הקובץ החדש מופרדים זה מזה בפסיקים. כך נראה הקובץ כאשר הוא נפתח ב”אקסל”:
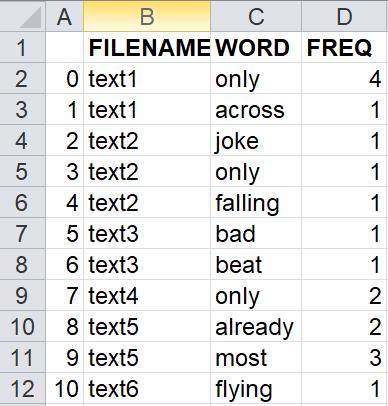
כפי שאפשר לראות הטבלה שנכתבה לקובץ כוללת עמודה שלא הייתה בקובץ המקורי: עמודה זו כוללת את האינדקסים של השורות. אם אין רצוננו שעמודה זו תיכתב בקובץ החדש נוכל לתת ארגומנט False לפרמטר index של הפונקציה to_csv, כך:
df.to_csv(‘newFreq.csv’, index = False)
בדומה נשתמש בפונקציה to_excel כדי לכתוב DataFrame בתור קובץ “אקסל”.
df.to_excel(‘newFreq.xlsx’, index = False)
(6) שמות משתנים ב-DataFrame
אובייקט של DataFrame מחזיק נתונים מגליון נתונים ומידע נוסף בנוגע לגליון. בין השאר הוא שומר את שמות המשתנים בגליון. השמות נשמרים במשתנה בשם columns. הוראה זו מדפיסה את תכנו:
print(df.columns)
>>>
Index([‘FILENAME’, ‘WORD’, ‘FREQ’], dtype=’object’)
לא נדון כאן בכל פרטי הפלט. נסתפק בהסבת תשומת הלב שאוסף שמות המשתנים תחום כאן בסוגריים מרובעים. ואכן אפשר להשתמש במשתנה columns כאילו היה רשימה. למשל באמצעות האופרטור [ ] נוכל לגשת אל שם מסוים השמור במשתנה:
print(df.columns[0])
>>>
FILENAME
שימו לב: בשמות משתנים ב-DataFrame יש חשיבות ל-case (“אות קטנה” ו”אות גדולה”): השם ‘FILENAME’ שונה מהשם ‘filename’.
אפשר לשנות שמות משתנים ב-DataFrame. נעשה זאת באמצעות הפונקציה rename. נעביר לפרמטר columns שלה מילון: המפתחות בו יהיו השמות הקיימים, והערכים יהיו השמות החדשים. דוגמה:
newDF = df.rename(columns = {‘FILENAME’:’file_name’,
‘FREQ’: ‘frequency’})
print(newDF.columns)
>>>
Index([‘file_name’, ‘WORD’, ‘frequency’], dtype=’object’)
תנו דעתכם שהפונקציה rename יצרה כאן DataFrame חדשה ובה השמות החדשים, והחזירה את הטבלה הזאת.
(7) סוגי ערכים בעמודות DataFrame
באובייקט DataFrame יש מידע בנוגע לסוגי הערכים במשתני הטבלה. מידע זה מוחזק במשתנה ששמו dtypes. נוכל להדפיס אותו כך:
print(df.dtypes)
>>>
FILENAME object
WORD object
FREQ int64
dtype: object
תנו דעתכם: לסוג המשתנה FILENAME ולסוג המשתנה FREQ ניתן כאן השם object. שם זה מציין מחרוזת או סוגי אוספים שיש בהם ערכים מסוגים מגוונים, כגון רשימה (list). לעומת זאת לסוג המשתנה FREQ ניתן השם int64. שם זה מציין מספרים שלמים. מתוך כך מתברר כי השכיחויות נטענו לתוך ה-DataFrame לא בתור מחרוזות כי אם בתור מספרים שלמים. פירוש הדבר הוא כי אפשר לבצע עליהן חישובים בלי צורך להמיר אותן קודם למספרים.
(8) ממדי DataFrame
יש בו באובייקט DataFrame מידע גם בנוגע לממדי הטבלה. מידע זה שמור בתור רשומה במשתנה בשם shape .
print(df.shape)
>>>
(11, 3)
נעיר כי כדי לקבל את מספר התצפיות בטבלה אפשר גם להפעיל את הפונקציה len על אובייקט ה-DataFrame, כך:
print(len(df))
>>>
11
(9) הדפסת DataFrame
כדי להדפיס DataFrame נוכל להשתמש בפונקציה print כך:
print(df)
>>>
FILENAME WORD FREQ
0 text1 only 4
1 text1 across 1
2 text2 joke 1
3 text2 only 1
4 text2 falling 1
5 text3 bad 1
6 text3 beat 1
7 text4 only 2
8 text5 already 2
9 text5 most 3
10 text6 flying 1
אם הטבלה גדולה יודפסו רק כמה עשרות שורות ראשונות וכמה עשרות שורות אחרונות. בנוסף יוצג מידע בנוגע לממדי הטבלה, לדוגמה:
[11 rows x 3 columns]
נשתמש בפונקציה head אם רצוננו להדפיס שורות ראשונות בלבד, למשל כך:
print(df.head(n = 2))
הפונקציה head יוצרת DataFrame חדשה ומחזירה אותה. בזימונה כאן העברנו את הארגומנט 2 לפרמטר n שלה, ופירוש הדבר שתוחזר DataFrame שמופיעות בה שתי השורות הראשונות ב-DataFrame המקורית. אפשר גם לזמן את הפונקציה head בלי לתת לה מספר שורות מבוקש:
print(df.head())
זימון הפונקציה head כאן יוצר DataFrame שמופיעות בה 5 השורות הראשונות בטבלה.
בדומה לאמור נשתמש בפונקציה tail להדפסת שורות אחרונות בטבלה. דוגמות:
print(df.tail(n = 7))
print(df.tail())
ההוראה השנייה כאן תדפיס את 5 השורות האחרונות ב-df.
(10) יצירת עותקים של מקטעי DataFrame
באמצעות האופרטור [ ] נוכל ליצור DataFrame חדשה שיש בה עמודה אחת או כמה עמודות מ-DataFrame נתונה. בתוך הסוגריים ניתן רשימה ובה מחרוזות המציינות את שמות המשתנים המבוקשים. דוגמה:
partialDF = df[[‘WORD’, ‘FILENAME’]]
print(partialDF)
>>>
WORD FILENAME
0 only text1
1 across text1
2 joke text2
3 only text2
4 falling text2
5 bad text3
6 beat text3
7 only text4
8 already text5
9 most text5
10 flying text6
כפי שאפשר להיווכח, סדר ציון שמות המשתנים אינו חייב להיות תואם לסדר הופעת המשתנים ב-DataFrame המקורית. תנו גם דעתכם שיש לכתוב את שמות המשתנים בדיוק כפי שהם שמורים ב-DataFrame המקורית, ביחוד מבחינת ה-case (“אות גדולה” ו”אות קטנה”).
אם נרצה שה-DataFrame החדשה תהיה חלקית לא רק מצד העמודות אלא גם מצד השורות, כלומר תכיל מקטע (רצוף) של אוסף השורות ב-DataFrame המקורית, נשתמש באופרטור של אובייקט DataFrame. שמו: loc. הפעלתו נעשית בדומה לזימון פונקציה של אובייקט DataFrame, אך שלא כמו בזימון פונקציה נכתוב לצד שמו סוגריים מרובעים ולא סוגריים עגולים. בתוך הסוגריים נכתוב טווח אינדקסים של רצף השורות המבוקש, פסיק, ורשימה ובה שמות העמודות שנרצה שייכללו ב-DataFrame החדשה (לפי הסדר הנדרש). דוגמה.
partialDF = df.loc[2:5, [‘WORD’, ‘FILENAME’]]
print(partialDF)
>>>
WORD FILENAME
2 joke text2
3 only text2
4 falling text2
5 bad text3
נוכל גם ‘לחתוך’ שורה אחת בלבד, אם נציין את האינדקס שלה במקום ציון טווח. דוגמה:
partialDF = df.loc[2, [‘WORD’, ‘FREQ’]]
print(partialDF)
>>>
WORD joke
FREQ 1
Name: 2, dtype: object
האובייקט שניתן לו כאן השם partialDF הוא אובייקט מסוג Series (ראו לעיל, סעיף 2). כדי לגשת לערכים מסוימים בערך מסוג Series נוכל להפעיל את האופטור [ ] עליו, בדומה להפעלתו על רשימה (list). דוגמה:
print(partialDF[1])
>>>
1
נוכל גם ליצור DataFrame שיש בה מקטע רצוף של שורות ועמודה אחת בלבד. במקרה זה אין הכרח לתת את תווית העמודה בתוך רשימה. דוגמה:
partialDF = df.loc[2:5, ‘WORD’]
print(partialDF)
>>>
2 joke
3 only
4 falling
5 bad
Name: WORD, dtype: object
גם קוד זה יוצר אובייקט מסוג Series.
נשתמש באופרטור אחר של אובייקט DataFrame, האופרטור iloc, כדי ליצור DataFrame חדשה שיש בה כל העמודות של DataFrame נתונה אך רק מקטע רצוף של שורות מה-DataFrame הנתונה. דוגמה:
partialDF = df.iloc[0:3]
print(partialDF)
>>>
FILENAME WORD FREQ
0 text1 only 4
1 text1 across 1
2 text2 joke 1
כאן כתבנו בתוך הסוגריים המרובעים טווח אינדקסים של שורות שייכללו בטבלה החדשה. כתמיד טווח האינדקסים בפועל אינו כולל את המספר המופיע מימין לסימן נקודתיים. אם כן הטבלה הנוצרת כאן מכילה את השורות שהאינדקסים שלהן ב-DataFrame המקורית הם 0, 1, 2, ולא את השורה שהאינדקס שלה הוא 3.
אם נרצה עותק של שורה אחת ב-DataFrame נתונה נפעיל את האופרטור iloc וניתן לו אך ורק את האינדקס של השורה הזאת. דוגמה:
secondRow = df.iloc[2]
print(secondRow)
>>>
FILENAME text2
WORD joke
FREQ 1
Name: 2, dtype: object
הערך המוצב כאן במשתנה secondRow הוא מסוג Series.
נעיר כי אפשר להשתמש באופרטור iloc גם כדי ליצור עותק חלקי של ה-DataFrame המכיל שורות מסוימות וגם עמודות מסוימות, נציין בתוך הסוגריים המרובעים אינדקסים או טווחים של אינדקסים עבור השורות ועבור העמודות (בסדר זה), ונפריד ביניהם בפסיק. הנה למשל דוגמה ליצירת DataFrame שמופיעות בה השורות באינדקסים 2 עד 4 של העמודה באינדקס 1 ב-DataFrame המקורית.
partialDF = df.iloc[2:5, 1]
print(partialDF)
>>>
2 joke
3 only
4 falling
Name: WORD, dtype: object
עם האמור בדרך כלל ביצירת עותק חלקי של ה-DataFrame שיש עמודות מסוימות, נעדיף לציין את התוויות של העמודות האלה ולא את האינדקסים שלהן, ולצורך כך נשתמש באופרטור loc.
(11) סינון
בסעיף הקודם ראינו כי באמצעות הפעלת האופרטור loc נוכל ליצור מ-DataFrame נתונה DataFrame חדשה שיש בה תצפיות רצופות מסוימות מה-DataFrame הנתונה. באמצעות הפעלת האופרטור [ ] על DataFrame נתונה אפשר לסנן תצפיות לפי תנאים. לשם כך נכתוב תנאים לוגיים בתוך הסוגרים המרובעים. דוגמה:
partialDF = df[df.WORD == ‘only’]
print(partialDF)
>>>
FILENAME WORD FREQ
0 text1 only 4
3 text2 only 1
7 text4 only 2
הפעלת האופרטור [ ] בדוגמה יוצרת DataFrame שמופיעות בה כל התצפיות ב-df שהמילה only מופיעה בהן בעמודת המשתנה WORD. שימו לב לתבנית הכתיבה בציון העמודה: שם ה-DataFrame, נקודה, ושם העמודה (לא בתור מחרוזת). אפשר גם להשתמש באופרטור [ ] ובתוך הסוגריים לכתוב את שם העמודה בתור מחרוזת. דוגמה:
partialDF = df[df[‘WORD’] == ‘only’]
דוגמה נוספת:
partialDF = df[df.WORD == df.loc[3, ‘WORD’]]
print(partialDF)
FILENAME WORD FREQ
0 text1 only 4
3 text2 only 1
7 text4 only 2
כאן הפעלת האופרטור [ ] על האובייקט df יוצרת DataFrame שמופיעות בה תצפיות ב-df המקיימות את התנאי הזה: בעמודת המשתנה WORD מופיעה בהן המילה אשר מופיעה בעמודת המשתנה הזה בתצפית השלישית (כלומר המילה only).
ביצירת ביטויים לוגיים מורכבים נשתמש בסימן & (ולא באופרטור and) עבור קשר “וגם”; נשתמש בסימן | (ולא באופרטור or) עבור קשר “או”; ונשתמש בסימן ~ (ולא באופרטור not) עבור קשר “לא”. דוגמה:
partialDF = df[(df.WORD == ‘only’) & (df.FREQ > 1)]
print(partialDF)
>>>
FILENAME WORD FREQ
0 text1 only 4
7 text4 only 2
כאן נוצרת DataFrame שמופיעות בה כל התצפיות ב-df שהמילה only מופיעה בהן בעמודת המשתנה WORD וגם השכיחות המופיעה בהן בעמודת המשתנה FREQ גדולה מ-1.
באמצעות הפונקציה isin אפשר לסנן תצפיות המכילות ערכים המופיעים ברשימה נתונה. פונקציה זו מחזירה True או False לפי בדיקת קיומו של ערך ברשימת ערכים (בדומה לאופרטור in). דוגמה:
shrinkedDF = df[df[‘WORD’].isin([‘only’, ‘joke’])]
print(shrinkedDF)
>>>
FILENAME WORD FREQ
0 text1 only 4
2 text2 joke 1
3 text2 only 1
7 text4 only 2
כאן בתוך הסוגריים המרובעים הופעלה הפונקציה isin על עמודת המשתנה WORD ובתור ארגומנט הועברה לפונקציה רשימה של מילים, [‘only’, ‘joke’]. הפונקציה מחזירה True רק עבור תצפיות שהערך המופיע בהן בעמודת המשתנה WORD מופיע ברשימה שהפונקציה isin קיבלה בתור ארגומנט. התצפיות האלה ייכללו בטבלה החדשה שתוצב במשתנה shrkinedDF .
ההוראה הזאת משתמשת באופרטור loc כדי ליצור DataFrame חדשה שיש בה רק את העמודות WORD ו-FREQ ורק את השורות שהשכיחות בהן קטנה מ-3:
partialDF = df.loc[df.FREQ < 3, [“WORD”, “FREQ”]]
print(partialDF)
>>>
WORD FREQ
1 across 1
2 joke 1
3 only 1
4 falling 1
5 bad 1
6 beat 1
7 only 2
8 already 2
10 flying 1
אפשר לסנן DataFrame גם לפי בדיקה אם ערך בעמודה מכיל רצף תווים מסוים (ראו להלן, סעיף 17.6).
(12) השמת ערך בתא, הוספת עמודות ועדכונן
נשים ערך בתא של DataFrame באמצעות האופרטור at. כמו לאופרטור loc (ראו הסעיף הקודם) גם לאופרטור at נלווים סוגריים מרובעים. בתוכם נכתב ביטוי המציין את המקום בטבלה שנמצא בו התא שערכו ישתנה. הביטוי הוא בתבנית זו: אינדקס שורה, פסיק, שם עמודה. דוגמה:
print(df.iloc[0])
df.at[0, ‘FREQ’] = 5
print(df.iloc[0])
>>>
FILENAME text1
WORD only
FREQ 4
Name: 0, dtype: object
FILENAME text1
WORD only
FREQ 5
Name: 0, dtype: object
ההוראה השנייה בקוד זה מציבה מספר בתא של df המצוי בשורה שהאינדקס שלה הוא 0 ובעמודה ששמה הוא FREQ: לאחר ביצועה יכיל תא זה את המספר 5 במקום המספר 4 ששכן בו קודם לכן. שימו לב: כאן אין נוצרת DataFrame חדשה; השינוי מתבטא ב-DataFrame שעליה מופעל האופרטור at.
כדי להוסיף עמודה חדשה (משתנה חדש) לסוף DataFrame נתונה (בלי ליצור DataFrame חדשה) נשתמש באופרטור [ ] באופן דומה לשימוש בו בהוספת זוג למילון. בתוך הסוגריים המרובעים נכתוב את שם המשתנה החדש (מחרוזת). אם השם הזה הוא שם של עמודה קיימת בטבלה, לא תתבצע פעולת הוספה של משתנה חדש אלא פעולה של עדכון ערכי המשתנה הקיים. דוגמה:
df[‘ADJUST’] = 0
print(df)
>>>
FILENAME WORD FREQ ADJUST
0 text1 only 4 0
1 text1 across 1 0
2 text2 joke 1 0
3 text2 only 1 0
4 text2 falling 1 0
5 text3 bad 1 0
6 text3 beat 1 0
7 text4 only 2 0
8 text5 already 2 0
9 text5 most 3 0
10 text6 flying 1 0
הוראת ההשמה הוסיפה ל-DataFrame עמודה (משתנה) בשם ADJUST ושָמה 0 בכל התאים בעמודה זו. אם לאחר ביצועה נריץ את ההוראה הזאת:
df[‘ADJUST’] = 1
יעודכנו כל הערכים במשתנה ADJUST – כולם ישתנו מ-0 ל-1.
אפשר לשים בעמודה החדשה (או: המעודכנת) ערכים שהם תוצאה של ביטויים מתמטיים ואחרים. ביטויים אלה יכולים להישען על ערכים בעמודות ה-DataFrame. למשל עיינו בקוד הזה:
df[‘DOUBLEFREQ’] = df[‘FREQ’] ** 2
print(df)
>>>
FILENAME WORD FREQ DOUBLEFREQ
0 text1 only 4 16
1 text1 across 1 1
2 text2 joke 1 1
3 text2 only 1 1
4 text2 falling 1 1
5 text3 bad 1 1
6 text3 beat 1 1
7 text4 only 2 4
8 text5 already 2 4
9 text5 most 3 9
10 text6 flying 1 1
כאן הוּסְפה לטבלה df עמודה חדשה בשם DOUBLEFREQ. בכל תא בעמודה זו הושם ערך שהוא תוצאה של ריבוע השכיחות המופיעה בשורה שהתא נמצא בה.
מה בדבר הוספת עמודה של משתנה קטגוריאלי? נניח למשל שנרצה להוסיף לטבלה df עמודה חדשה בשם FREQ_CATS. עמודה זו מכילה ארבע קטגוריות לשכיחויות, כדלקמן: A – שכיחות עד 1, כולל; B – שכיחות מעל 1 ועד 2, כולל; C – שכיחות מעל 2 ועד 3, כולל; D – שכיחות מעל 3 ועד 4, כולל; E – שכיחות מעל 4. אפשר להוסיף את העמודה החדשה באמצעות קטע הקוד הזה:
df[“FREQ_CATS”] = “E”
df.loc[df.FREQ <= 4, “FREQ_CATS”] = “D”
df.loc[df.FREQ <= 3, “FREQ_CATS”] = “C”
df.loc[df.FREQ <= 2, “FREQ_CATS”] = “B”
df.loc[df.FREQ <= 1, “FREQ_CATS”] = “A”
ההוראה הראשונה יוצרת את העמודה הדחשה ושמה E בכל תאיה. ההוראות הבאות מעדכנות את התאים בעמודה הזאת לפי בדיקה של השכיחות. העדכון מתבצע באמצעות האופרטור loc בתחביר הבוחר שורות מעמודה מסוימת לפי תנאי. למשל ההוראה השניה מציבה D אך ורק בעמודה FREQ_CATS ובשורות שהערכים בעמודת השכיחות בהן קטנים או שווים ל-4.
(13) מחיקת עמודות ושורות
כדי למחוק עמודה מ-DataFrame נוכל להשתמש באופרטור del . גם הפעם נציין בסוגריים המרובעים מחרוזת – כאן: שם המשתנה למחיקה. דוגמה:
del df[‘FREQ’]
כאן נמחק מ-df המשתנה FREQ. שימו לב שהשינוי נעשה ב-DataFrame עצמה ואין נוצרת DataFrame חדשה.
אפשר למחוק עמודות מ-DataFrame גם באמצעות הפונקציה drop. דוגמה:
newDF = df.drop(columns = ‘WORD’)
print(newDF)
>>>
FILENAME FREQ
0 text1 4
1 text1 1
2 text2 1
3 text2 1
4 text2 1
5 text3 1
6 text3 1
7 text4 2
8 text5 2
9 text5 3
10 text6 1
בזימון זה נתנו שם של עמודה – WORD – לפרמטר columns של הפונקציה drop . הזימון יחזיר DataFrame חדשה שאין מופיעה בה העמודה שזה שמה. הפונקציה יכולה גם למחוק את העמודה מה-DataFrame שהיא פועלת עליה בלי ליצור DataFrame חדשה. הדבר נעשה באמצעות העברת הערך True לפרמטר אחר של הפונקציה, inplace. דוגמה:
df.drop(columns=’WORD’, inplace = True)
print(df)
>>>
FILENAME FREQ
0 text1 4
1 text1 1
2 text2 1
3 text2 1
4 text2 1
5 text3 1
6 text3 1
7 text4 2
8 text5 2
9 text5 3
10 text6 1
אפשר להעביר לפרמטר columns רשימה של שמות עמודות למחיקה. דוגמה:
newDF = df.drop(columns=[‘WORD’, ‘FREQ’])
בדומה לאמור, אם נרצה למחוק שורות מ-DataFrame נעביר אינדקס או רשימת אינדקסים לפרמטר index של הפונקציה drop. דוגמות:
newDF = df.drop(index = 1)
newDF = df.drop(index = [1, 2, 3, 4])
כל אחת משתי ההוראות האלה יוצרת DataFrame לפי df. ב-DataFrame שיוצרת ההוראה הראשונה מופיעות כל השורות ב-df חוץ מזו שהאינדקס שלה הוא 1. ב-DataFrame שיוצרת ההוראה השנייה מופיעות כל השורות ב-df חוץ מאלו שהאינדקסים שלהן הם 1, 2, 3 ו-4.
באמצעות הפונקציה drop אפשר גם למחוק מ-DataFrame שורות לפי תנאים. נעשה זאת בשני שלבים. בשלב ראשון נשתמש באופרטור index כדי ליצור רשימה של אינדקסים של שורות המקיימות תנאי. דוגמה:
indices = df[df[‘WORD’].isin([‘only’, ‘joke’])].index
print(indices)
>>>
Int64Index([0, 2, 3, 7], dtype=’int64′)
בצד הימני של הוראת ההשמה מופעל האופרטור [ ] כדי למצוא שורות שהמילה only או המילה joke מופיעות בהן בעמודה WORD. מימין לסוגר המרובע הסוגר כתבנו נקודה ואת שם האופרטור index. האופרטור מחזיר מבנה נתונים המכיל את כל האינדקסים של השורות המקיימות את התנאי, כלומר 0, 2, 3 ו-7. מבנה נתונים זה אינו רשימה (list), אך אפשר להשתמש בו כדי להעביר “רשימת” אינדקסים לפונקציה drop, כך:
newDF = df.drop(index = indices)
print(newDF)
>>>
FILENAME WORD FREQ
1 text1 across 1
4 text2 falling 1
5 text3 bad 1
6 text3 beat 1
8 text5 already 2
9 text5 most 3
10 text6 flying 1
כאמור נוכל להסיר את השורות הממלאות את התנאי מ-df עצמה (ולא ליצור DataFrame חדשה) אם נעביר את הערך True לפרמטר inplace .
באמצעות הפונקציה dropna נוכל למחוק מ-DataFrame את כל השורות שיש בהן ערכים חסרים. דוגמה:
df.dropna(inplace = True)
אם לא נעביר ערך לפרמטר inplace ההשמטה לא תעשה במקום ותוחזר DataFrame חדשה שאין בה את השורות ב-df מ שיש בהן ערכים חסרים.
(14) מיון
נמיין DataFrame באמצעות הפונקציה sort_value. דוגמה:
sortedDF = df.sort_values(by = [‘WORD’])
print(sortedDF)
>>>
FILENAME WORD FREQ
1 text1 across 1
8 text5 already 2
5 text3 bad 1
6 text3 beat 1
4 text2 falling 1
10 text6 flying 1
2 text2 joke 1
9 text5 most 3
0 text1 only 4
3 text2 only 1
7 text4 only 2
הוראה זו יוצרת DataFrame ממוינת לפי ה-DataFrame הנתונה df. הארגומנט המועבר בזימון זה לפרמטר by קובע את משתנה המיון – כאן: WORD. ברירת המחדל היא שהמיון הוא בסדר מילוני עולה (או לשם דיוק: לא יורד). אפשר לשנות את סדר המיון באמצעות קביעת ערכו של הפרמטר ascending. דוגמה:
sortedDF = df.sort_values(by = [‘WORD’], ascending = False)
print(sortedDF)
>>>
FILENAME WORD FREQ
0 text1 only 4
3 text2 only 1
7 text4 only 2
9 text5 most 3
2 text2 joke 1
10 text6 flying 1
4 text2 falling 1
6 text3 beat 1
5 text3 bad 1
8 text5 already 2
1 text1 across 1
כאן sortedDF ממוינת בסדר יורד (למעשה: לא עולה) לפי המשתנה WORD.
אפשר להגדיר מיון לפי יותר מרמה אחת. נעשה זאת באמצעות הוספת משתנים לרשימה המועברת לפרמטר by. המשתנה הראשון יציין רמת מיון ראשונה, המשתנה השני יציין רמת מיון שנייה, וכן הלאה. דוגמה:
sortedDF = df.sort_values(by = [‘WORD’, ‘FREQ’], ascending = False)
print(sortedDF)
>>>
FILENAME WORD FREQ
0 text1 only 4
7 text4 only 2
3 text2 only 1
9 text5 most 3
2 text2 joke 1
10 text6 flying 1
4 text2 falling 1
6 text3 beat 1
5 text3 bad 1
8 text5 already 2
1 text1 across 1
כאן מתבצע מיון ראשי לפי המשתנה WORD ומיון משני לפי המשתנה FREQ. שני המיונים יעשו בסדר יורד. אפשר לקבוע סדרי מיון בלתי אחידים לרמות המיונים באמצעות העברת רשימת ערכים בוליאנים לפרמטר ascending. דוגמה:
newDF = df.drop(columns=[‘WORD’, ‘FREQ’])
בדומה לאמור, אם נרצה למחוק שורות מ-DataFrame נעביר אינדקס או רשימת אינדקסים לפרמטר index של הפונקציה drop. דוגמות:
sortedDF = df.sort_values(by = [‘WORD’, ‘FREQ’], ascending = [True, False])
print(sortedDF)
>>>
FILENAME WORD FREQ
1 text1 across 1
8 text5 already 2
5 text3 bad 1
6 text3 beat 1
4 text2 falling 1
10 text6 flying 1
2 text2 joke 1
9 text5 most 3
0 text1 only 4
7 text4 only 2
3 text2 only 1
ההוראה כאן מבצעת מיון ראשי לפי המשתנה WORD בסדר עולה, ומיון משני לפי המשתנה FREQ בסדר יורד.
כפי שאפשר לראות בדוגמות למיון למעלה, בטבלה הממוינת האינדקסים של השורות “זזים” לפי המיון. באמצעות הפונקציה reset_index() אפשר לאתחל את האינדקסים בטבלה הממוינת. אם לא נעביר לה ארגומנטים היא תיצור DataFrame חדשה ובה תאותחל מערכת האינדקסים של השורות, ותחזיר DataFrame זו. האתחול יעשה במקום אם נעביר את הערך True לפרמטר inplace שלה. דוגמה:
sortedDF.reset_index(inplace = True)
print(sortedDF)
>>>
index FILENAME WORD FREQ
0 1 text1 across 1
1 8 text5 already 2
2 5 text3 bad 1
3 6 text3 beat 1
4 4 text2 falling 1
5 10 text6 flying 1
6 2 text2 joke 1
7 9 text5 most 3
8 0 text1 only 4
9 7 text4 only 2
10 3 text2 only 1
שימו לב שהאינדקסים המקוריים הוספו כאן ל-DataFrame בתור עמודה ראשונה. אפשר למנוע זאת באמצעות העברת True לפרמטר drop של הפונקציה reset_index. דוגמה:
sortedDF.reset_index(inplace = True, drop = True)
print(sortedDF)
>>>
FILENAME WORD FREQ
0 text1 across 1
1 text5 already 2
2 text3 bad 1
3 text3 beat 1
4 text2 falling 1
5 text6 flying 1
6 text2 joke 1
7 text5 most 3
8 text1 only 4
9 text4 only 2
10 text2 only 1
כאן לא הוספה עמודת האינדקסים המקוריים ל-DataFrame הממוינת.
(15) קיבוץ
אפשר ליצור קבוצות של תצפיות ב-DataFrame. הקיבוץ נעשה באמצעות הפונקציה groupby ובדרך כלל לפי משתנה שמי. דוגמה:
groupings = df.groupby(‘FILENAME’)
בסוף ביצוע ההוראה הזאת יכיל המשתנה groupings אובייקט השומר קבוצות של תצפיות, לפי שם הקובץ FILENAME: קבוצת התצפיות שמופיעה בהן המחרוזת ‘text1’ במשתנה FILENAME, קבוצת התצפיות שמופיעה בהן המחרוזת ‘text2’ במשתנה FILENAME, וכן הלאה. באמצעות הפעלת הפונקציה size על האובייקט שמחזירה הפונקציה groupby נוכל לבדוק את גדלי הקבוצות. דוגמה:
print(groupings.size())
>>>
FILENAME
text1 2
text2 3
text3 2
text4 1
text5 2
text6 1
dtype: int64
לפי פלט זה יש שתי תצפיות בקבוצת התצפיות הנוגעות לקובץ text1, שלוש תצפיות בקבוצת התצפיות הנוגעות לקובץ text2, וכן הלאה.
זימון הפונקציה get_group באמצעות האובייקט שמחזירה הפונקציה groupby יוצר DataFrame המכילה את כל התצפיות בקבוצה מסוימת כרצוננו. דוגמה:
groupDF = groupings.get_group(‘text1’)
print(groupDF)
>>>
FILENAME WORD FREQ
0 text1 only 4
1 text1 across 1
כאן יצרנו DataFrame המכילה את כל התצפיות בקובץ הנתונים המקורי שמופיע בהן המחרוזת ‘text1’ במשתנה FILENAME.
נוכל לקבץ לפי יותר ממשתנה אחד. לשם כך נעביר לפונקציה groupby רשומה של שמות משתני הקיבוץ. דוגמה:
groupings = df.groupby([‘FILENAME’, ‘FREQ’])
groupDF = groupings.get_group((‘text2’, 1))
print(groupDF)
>>>
FILENAME WORD FREQ
2 text2 joke 1
3 text2 only 1
4 text2 falling 1
ההוראה הראשונה בקוד יוצרת אובייקט המכיל קבוצה לכל זוג של שם קובץ וערך שכיחות. ההוראה השנייה יוצרת DataFrame מהתצפיות של הקבוצה התואמת לזוג ‘text2’ (שם קובץ) ו-1 (שכיחות). הערכים בזוג מועברים לפונקציה get_group בתור רשומה.
(16) חישובים מתמטיים וסטטיסטיים
אפשר להפעיל מגוון פונקציות מתמטיות וסטטיסטיות על הערכים בעמודות DataFrame. דוגמה:
meanFreqs = df[‘FREQ’].mean()
print(meanFreqs)
>>>
1.6363636363636365
כאן מופעלת הפונקציה mean() על עמודת השכיחויות (למעשה על עותק שלה), ומחזירה את ממוצע השכיחויות. באופן דומה אפשר למצוא את השכיחות המינימלית, השכיחות המקסימלית, את סכום השכיחויות, את השונות של השכיחויות ואת סטיית התקן של השכיחויות, כך:
print(df[‘FREQ’].min())
print(df[‘FREQ’].max())
print(df[‘FREQ’].sum())
print(df[‘FREQ’].var())
print(df[‘FREQ’].std())
>>>
1
4
18
1.0545454545454542
1.026910636104941
נוכל להגדיר שהחישובים ייעשו לפי שורה ולא לפי עמודה באמצעות העברת 1 לפרמטר axis. נניח למשל שהטבלה שלנו כוללת, נוסף על עמודת השכיחות FREQ, עמודה נוספת בשם FREQ_ED2 המתעדת את שכיחויות המילים במהדורה השנייה של הספר:
FILENAME WORD FREQ FREQ_ED2
0 text1 only 4 6
1 text1 across 1 3
2 text2 joke 1 3
3 text2 only 1 3
4 text2 falling 1 3
5 text3 bad 1 3
6 text3 beat 1 3
7 text4 only 2 4
8 text5 already 2 4
9 text5 most 3 5
10 text6 flying 1 3
נזמן את הפונקציה mean באמצעות אובייקט ה-DataFrame ונעביר אליה 1 בתור ארגומנט לפרמטר axis. הפונקציה תחשב את ממוצע המספרים בעמודות המכילות מספרים – כאן: FREQ ו-FREQ_ED2:
df.mean(axis = 1)
>>>
0 5.0
1 2.0
2 2.0
3 2.0
4 2.0
5 2.0
6 2.0
7 3.0
8 3.0
9 4.0
10 2.0
dtype: float64
הפונקציה count סופרת כמה ערכים לא חסרים יש בעמודה. דוגמה:
print(df[‘FREQ’].count())
>>>
11
הפונקציה describe מופעלת על עמודה של DataFrame ומציגה מספר מדדים סטטיסטיים על הערכים בעמודה:
print(df[‘FREQ’].describe())
>>>
count 11843.000000
mean 1.341805
std 0.966696
min 1.000000
25% 1.000000
50% 1.000000
75% 1.000000
max 17.000000
Name: FREQ, dtype: float64
count – מספר ערכי השכיחות בעמודה; mean – ממוצע השכיחויות; std – סטיית התקן; min – שכיחות מינימלית; 25%, 50%, 75% – רבעון ראשון, חציון, רבעון שלישי; max – שכיחות מקסימלית. float64 פירושו הוא כי מבחינת החישובים ערכי השכיחות נחשבים למספרים עשרוניים. כל החישובים מתעלמים מערכים חסרים.
זימון הפונקציה describe() כך:
df.describe()
יחזיר את המדדים האמורים לכל המשתנים בטבלה df.
באמצעות הפונקציה value_counts המופעלת על עמודה של DataFrame ניצור אובייקט מסוג Series המכיל שכיחויות של ערכים בעמודה. דוגמה:
wordFreqs = df[‘WORD’].value_counts()
print(wordFreqs)
>>>
only 3
bad 1
most 1
across 1
joke 1
flying 1
beat 1
already 1
falling 1
Name: WORD, dtype: int64
זימון הפונקציה value_counts כאן החזיר אובייקט מסוג Series המכיל את השכיחויות של כל המילים (השונות זו מזו) המופיעות בעמודת המשתנה WORD.
(17) פעולות שימושיות נוספות
נציג כאן בקיצור נמרץ כמה פעולות שימושיות נוספות בטיפול בטבלאות מסוג DataFrame.
(17.1) יצירת DataFrame ממילון ויצירת מילון מ-DataFrame
הפונקציה DataFrame של pandas יוצרת DataFrame. היא יכולה ליצור לפי מילון. מפתחות המילון הם שמות המשתנים ב-DataFrame, וערכי המילון הם ערכי המשתנים. דוגמה:
df = pd.DataFrame({‘FILENAME’:[‘text1’, ‘text2’],
‘WORD’ :[‘the’, ‘and’],
‘FREQ’ :[15, 12]})
print(df)
>>>
FILENAME WORD FREQ
0 text1 the 15
1 text2 and 12
המילון יכול להכיל ערכים חסרים. נציין אותם באמצעות הערך nan (נייבא אותו במפורש מהספרייה numpy).
from numpy import nan
df = pd.DataFrame({‘FILENAME’:[‘text1’, nan],
‘WORD’ :[‘the’, ‘and’],
‘FREQ’ :[nan, 12]})
print(df)
>>>
FILENAME WORD FREQ
0 text1 the NaN
1 NaN and 12.0
באמצעות הפונקציה to_dict אפשר להמיר DataFrame למילון. דוגמה:
print(df.to_dict(orient = ‘list’))
>>>
{‘FILENAME’: [‘text1’, ‘text2’], ‘WORD’: [‘the’, ‘and’], ‘FREQ’: [15, 12]}
כאן העברנו את המחרוזת ‘list’ לפרמטר orient של הפונקציה to_dict . העברת ארגומנט זה גרמה ליצירת מילון שכל מפתח בו הוא שם משתנה וכל ערך הוא רשימה של הערכים במשתנה זה. אם נפעיל את הפונקציה to_dict ללא ארגומנטים כלל הערכים במילון המתקבל יהיו עצמם מילונים. המילונים האלה יכילו את הערכים במשתני ה-DataFrame ואת האינדקסים של השורות שהערכים נמצאים בהן, בתור מפתחות. דוגמה:
print(df.to_dict())
>>>
{‘FILENAME’: {0: ‘text1’, 1: ‘text2’}, ‘WORD’: {0: ‘the’, 1: ‘and’}, ‘FREQ’: {0: 15, 1: 12}}
המילון המשויך למפתח ‘FILENAME’ מציין כי במשתנה שזה שמו מופיעה המחרוזת ‘text1’ בשורה שהאינדקס שלה הוא 0, והמחרוזת ‘text2’ בשורה שהאינדקס שלה הוא 1.
(17.2) המרת עמודה לרשימה
כדי להמיר עמודה ב-DataFrame לרשימה נשתמש בפונקציה tolist. דוגמה:
print(df[‘WORD’].tolist())
>>>
[‘only’, ‘across’, ‘joke’, ‘only’, ‘falling’, ‘bad’, ‘beat’, ‘only’, ‘already’, ‘most’, ‘flying’]
(17.3) יצירת מדגם תצפיות
נשתמש בפונקציה sample כדי ליצור DataFrame שהיא מדגם תצפיות של DataFrame נתונה. נעביר את גודל המדגם (מספר השורות ב-DataFrame הנוצרת) לפרמטר n של הפונקציה. אם נרצה דגימה עם החזרה נעביר גם True לפרמטר replace. דוגמה:
sampleDF = df.sample(n = 10, replace = True)
print(sampleDF)
>>>
FILENAME WORD FREQ
1 text1 across 1
10 text6 flying 1
10 text6 flying 1
3 text2 only 1
5 text3 bad 1
8 text5 already 2
5 text3 bad 1
6 text3 beat 1
0 text1 only 4
9 text5 most 3
תנו דעתכם שיש כפילויות בתצפיות מדגם זה, וכי נשמרים בו האינדקסים של השורות ב-DataFrame המקורית. נעיר גם כי אפשר למיין את מדגם התצפיות לפי אינדקסים באמצעות הפונקציה sort_index .
(17.4) הסרת כפילויות
הפונקציה drop_duplicates מוציאה כפילויות משורות DataFrame. לדוגמה נעיין בקוד המטפל במדגם התצפיות sampleDF שיצרנו בסעיף הקודם:
sampleDF = df.sample(n = 10, replace = True)
partialDF = sampleDF.drop_duplicates()
print(partialDF)
>>>
FILENAME WORD FREQ
1 text1 across 1
10 text6 flying 1
3 text2 only 1
5 text3 bad 1
8 text5 already 2
6 text3 beat 1
0 text1 only 4
9 text5 most 3
השימוש בפונקציה drop¬_duplicates הסיר כפילויות ממדגם התצפיות sampleDF.
ברירת המחדל היא שתוכנס ל-DataFrame החדשה השורה הראשונה בכל קבוצה של שורות זהות. אפשר לשנות זאת באמצעות העברת ערך לפרמטר keep של הפונקציה drop_duplicates, כך:
partialDF = sampleDF.drop_duplicates(keep = ‘last’)
כאן העברנו את המחרוזת ‘last’ לפרמטר keep. בכך קבענו שתוכנס ל-DataFrame החדשה השורה האחרונה בכל קבוצה של שורות זהות.
נוכל להסיר כפילויות לפי עמודה מסוימת ולא לפי מלוא השורות. למשל אם נרצה ליצור מה-DataFrame המקורית (df) DataFrame חדשה שאין בה כפילויות בעמודת המילים, נכתוב כך:
shrinkedDF = df.drop_duplicates(subset = ‘WORD’)
כדי להסיר כפילויות מעמודת WORD העברנו את שם העמודה הזאת לפרמטר subset של הפונקציה drop_duplicates .
(17.5) ערכים ייחודיים בעמודה
כדי לקבל אוסף של כל הערכים השונים זה מזה במשתנה של DataFrame נפעיל על משתנה זה את הפונקציה unique באמצעות אובייקט ה-pandas (שיצרנו בייבוא החבילה הזאת). דוגמה:
uniqueValues = pd.unique(df.FILENAME)
>>>
[‘text1’ ‘text2’ ‘text3’ ‘text4’ ‘text5’ ‘text6’]
כאן הופעלה הפונקציה על המשתנה FILENAME. זימונה החזיר מבנה נתונים השומר את כל ערכי המשתנה השונים זה מזה, כלומר את כל שמות הקבצים, בלי כפילויות. כדי לגשת לערכים מסוימים בו במבנה נתונים זה (המוגדר בספריה numpy) אפשר להפעיל את האופרטור [ ]. דוגמה:
print(uniqueValues[0])
>>>
text1
כדי למצוא את מספר הערכים הייחודיים בעמודה נוכל להשתמש בפונקציה len כך:
len(pd.unique(df.FILENAME))
ונוכל גם להפעיל את הפונקציה nunique על המשתנה עצמו, כך:
df.FILENAME.nunique()
(17.6) הפעלת פעולות במחרוזות על ערכים בעמודה
אפשר להפעיל פעולות במחרוזות על כלל המחרוזות המופיעות בעמודה מסוימת. הדבר נעשה באמצעות הפעלת האופרטור str על העמודה, ואז הפעלת הפונקציה על ערך שמחזיר האופרטור הזה. דוגמה:
print(df[‘WORD’])
df[‘WORD’] = df[‘WORD’].str.upper()
print(df[‘WORD’])
>>>
0 the
1 and
Name: WORD, dtype: object
0 THE
1 AND
Name: WORD, dtype: object
ההוראה השנייה בקוד הדוגמה הפכה את כל המחרוזות בעמודה WORD ל-upper case.
פונקציה מועילה שאפשר להפעיל על מחרוזות בעמודה היא contains. פונקציה זו בודקת עבור כל מחרוזות בעמודה (או עבור כל ערך בעמודה שהומר למחרוזת, כאמור באמצעות האופרטור str), אם היא מכילה מחרוזת מסוימת. לפי זה היא יוצרת Series המכילה ערכים בוליאנים. דוגמה:
print(df[‘WORD’].str.contains(‘ing’))
>>>
0 False
1 False
2 False
3 False
4 True
5 False
6 False
7 False
8 False
9 False
10 True
Name: WORD, dtype: bool
אפשר להשתמש בערך ההחזרה של הפונקציה contains כדי לסנן תצפיות מהטבלה. לדוגמה אם נרצה ליצור DataFrame המכילה רק שורות שמופיעות בהן מילים המסתיימות ב-ing נכתוב כך:
נכתוב כך:
print(df[df[‘WORD’].str.contains(‘ing’)])
>>>
FILENAME WORD FREQ
4 text2 falling 1
10 text6 flying 1
(17.7) סריקת שורות
אפשר לסרוק DataFrame בלולאת for. דוגמה:
for index, row in df.iterrows():
print(index, row[‘WORD’])
>>>
0 only
1 across
2 joke
3 only
4 falling
5 bad
6 beat
7 only
8 already
9 most
10 flying
הפונקציה iterrows יוצרת מבנה נתונים המכיל שורות ב-DataFrame ונועד לשמש בלולאת for הסורקת שורות אלה. בכל סיבוב מוצבים אינדקס השורה והשורה עצמה במשתני הלולאה index ו-row (בסדר זה). בגוף הלולאה נוכל לגשת לערך הנמצא במשתנה מסוים בשורה הנוכחית באמצעות הפעלת האופרטור [ ] על המשתנה המחזיק את השורה – כאן: row – וכתיבת שם המשתנה בין הסוגריים. הלולאה בדוגמה מדפיסה את המילים בכל שורות הטבלה, ולפני כל מילה מודפס אינדקס השורה שהמילה נמצאת בה.
(17.8) יצירת טבלת שכיחויות לשני משתנים
ניצור טבלת שכיחויות לשני משתנים באמצעות הפונקציה crosstab. נפעיל אותה באמצעות אובייקט ה-pandas (שיצרנו בעת ייבואהּ). נניח למשל שה-DataFrame כוללת את המשתנה PartOfSpeech כדלקמן:
FILENAME WORD FREQ PartOfSpeech
0 text1 only 4 adjective
1 text1 across 1 preposition
2 text2 joke 1 noun
3 text2 only 1 adjective
4 text2 falling 1 noun
5 text3 bad 1 adjective
6 text3 beat 1 noun
7 text4 only 2 adjective
8 text5 already 2 adverb
9 text5 most 3 adverb
10 text6 flying 1 noun
כך ניצור טבלת שכיחויות דו-משתני לפי שמות הספרים ולפי חלקי הדיבר:
pd.crosstab(df.FILENAME, df.WORD)
>>>
PartOfSpeech adjective adverb noun preposition
FILENAME
text1 1 0 0 1
text2 1 0 2 0
text3 1 0 1 0
text4 1 0 0 0
text5 0 2 0 0
text6 0 0 1 0
הפונקציה crosstab מקבלת את משתנה השורות ומשתנה העמודות, בסדר זה.
אפשר להציג שכיחויות יחסיות לפי באמצעות העברת מחרוזת לפרמטר normalize: ‘all’ – לפי כלל התצפיות, ‘index’ לפי שורות, ‘columns’ לפי עמודות. הנה למשל השכיחויות היחסיות לפי עמודות:
pd.crosstab(df.FILENAME, df.PartOfSpeech, normalize = ‘columns’)
>>>
PartOfSpeech adjective adverb noun preposition
FILENAME
text1 0.25 0.0 0.00 1.0
text2 0.25 0.0 0.50 0.0
text3 0.25 0.0 0.25 0.0
text4 0.25 0.0 0.00 0.0
text5 0.00 1.0 0.00 0.0
text6 0.00 0.0 0.25 0.0
(18) דוגמה מעשית
הדוגמות שהוצגו בסעיפים הקודמים השתמשו כולן בגרסה מוקטנת של גליון נתונים המתעד שכיחויות של מילים בספרים. גליון זה שמור בקובץ freqFull.csv (לחצו על שמו כדי להורידו), ויש בו 11843 תצפיות על אודות שכיחויות של מילים ב-50 ספרים. נכתוב תכנית המוצאת את המילה השכיחה ביותר בכל הספרים (נניח שיש רק מילה אחת כזו). לצורך כך:
• ראשית נמצא את השכיחות הממוצעת של כל מילה ומילה בכל הספרים כולם. חישוב שכיחות זו ייעשה כך: סכום השכיחויות של המילה בכל הספרים שהיא מופיעה בהם, חלקי מספר הספרים שהיא מופיעה בהם.
• אחר כך ניצור DataFrame המציגה את המילים בכל הקבצים ואת שכיחויותיהן הממוצעות. הטבלה תהיה ממוינת לפי השכיחויות, בסדר יורד.
• אחר כך נדפיס את המילה שהשכיחות שלה היא המקסימלית.
• בנוסף ניצור מה-DataFrame הממוינת DataFrame שיש בה מידע על אודות עשר המילים השכיחות ביותר.
• נאתחל את האינדקסים ב-DataFrame זו.
• ולבסוף נשמור את ה-DataFrame בקובץ חדש.
להלן מוצגים הצעדים המרכיבים את מימוש התכנית. כדאי לעקוב אחר ביצוע הקוד באמצעות הרצתו צעד אחר צעד, והדפסת התוצאה של כל צעד.
צעד 1 – ייבוא pandas
import pandas as pd
צעד 2 – טעינת גליון הנתונים ל-DataFrame
df = pd.read_csv(‘freqFull.csv’)
צעד 3 – הוספת עמודה חדשה שתכיל את השכיחויות הממוצעות, ואתחול הערכים בה; שם העמודה: TOTAL
df[‘TOTAL’] = 0.0
צעד 4 – חישוב השכיחויות הממוצעות
for i in range(df.shape[0]):
partialDF = df[df.WORD == df.loc[i, ‘WORD’]]
frequenciesSum = partialDF[‘FREQ’].sum()
booksNum = partialDF.FILENAME.nunique()
df.at[i, ‘TOTAL’] = frequenciesSum / booksNum
לולאה זו סורקת את האינדקסים של כל השורות ב-DataFrame, החל מאינדקס 0 ועד לאינדקס של השורה האחרונה (אינדקס זה שווה למספר השורות בטבלה, כלומר ל-df.shape[0]).
כל סיבוב של הלולאה מבצע כמה פעולות עבור השורה הנסרקת הנוכחית (זו שהאינדקס שלה הוצב במשתנה הלולאה i), כדלקמן:
• הסיבוב מתחיל ביצירת DataFrame שיש בה אך ורק את התצפיות (השורות) שמופיעה בהן (בעמודה WORD) המילה בשורה הנסרקת הנוכחית.
• לאחר מכן מחושבים סכום השכיחויות בכל התצפיות ב-DataFrame הזאת (החישוב מניח שהשכיחויות נשמרות בתור מספרים), ומספר הספרים שהיא מופיעה בהם.
• לבסוף סכום השכיחויות מחולק במספר הספרים והתוצאה (הממוצע) מושם בתא בעמודה TOTAL המופיע בשורה הנוכחית.
בתום ביצוע הלולאה כל שורה תכיל בעמודה TOTAL את השכיחות הממוצעת של המילה המופיעה בשורה, ובכל השורות שמופיעה בהן מילה שווה תופיעה שכיחות אחת מסוימת בעמודה TOTAL.
צעד 5 – יצירת DataFrame חלקית המכילה אך ורק את עמודת המילים ועמודת השכיחויות
partialDF = df[[‘WORD’, ‘TOTAL’]]
צעד 6 – יצירת DataFrame שאין בה כפילויות בעמודת המילים
shrinkedDF = partialDF.drop_duplicates(subset = ‘WORD’)
צעד זה יוצר DataFrame המכילה את השכיחויות הממוצעות של המילים בכל הקבצים, ללא כפילויות.
צעד 7 – מיון ה-DataFrame המצומצמת לפי המילים, בסדר יורד
dfSorted=shrinkedDF.sort_values(by=[‘TOTAL’], ascending=False)
צעד 8 – אתחול האינדקסים של השורות ב-DataFrame שהתקבלה; נימנע מהשארת האינדקסים המקוריים
dfSOrted.reset_index(inplace = True, drop = True)
צעד 9 – הדפסת המילה השכיחה ביותר
print(dfSorted.loc[0, ‘WORD’])
צעד 10 – יצירת DataFrame חדשה מעשר השורות הראשונות ב-dfSorted
resultDF = dfSorted[0:10]
צעד 11 – כתיבת ה-DataFrame שהתקבלה, ללא עמודה לאינדקסים, בקובץ חדש בתיקיה המוגדרת בתור תיקיית העבודה
resultDF.to_csv(‘resultDF.csv’, index = False)
הנה הקוד במלואו, וה-DataFrame שהוא יוצר:
import pandas as pd
df = pd.read_csv(‘freq.csv’)
df[‘TOTAL’] = 0.0
for i in range(df.shape[0]):
partialDF = df[df.WORD == df.loc[i, ‘WORD’]]
frequenciesSum = sum(partialDF[‘FREQ’])
booksNum = partialDF.FILENAME.nunique()
df.at[i, ‘TOTAL’] = frequenciesSum / booksNum
#df.to_csv(‘total.csv’, index = False)
partialDF = df[[‘WORD’, ‘TOTAL’]]
shrinkedDF = partialDF.drop_duplicates(subset = ‘WORD’)
dfSorted = shrinkedDF.sort_values(by=[‘TOTAL’], ascending=False)
dfSorted.reset_index(inplace = True, drop = True)
print(dfSorted.loc[0, ‘WORD’])
resultDF = dfSorted[0:10]
resultDF.to_csv(‘resultDF.csv’, index = False)
print(resultDF)
>>>
wealth
WORD TOTAL
0 wealth 11.0
1 racism 9.0
2 dictionari 8.0
3 nft 8.0
4 nurseri 8.0
5 epic 8.0
6 palestinian 8.0
7 plastic 7.5
8 cathol 7.0
9 bu 7.0
מתברר שהמילה השכיחה ביותר בכל הספרים היא wealth .