פרק שביעי
קריאה מקובץ טקסט, כתיבה בו, ופעולות נוספות במחרוזות

תוכן העניינים
הוראות המופיעות בגוף של מבנה while ומתבצעות כל עוד תנאי הלולאה מתקיים צריכות להיות מוזזות ימינה ביחס לשורה הראשונה במבנה. הקוד התקין:
age = input(‘Insert age; -1 to stop: ‘)
while age != ‘-1’:
print(age)
age = input(‘Insert age; -1 to stop: ‘)
(1) מבוא
לתכנית פייתון יש על פי רוב שלושה חלקים עיקריים אלה: קליטת נתונים, עיבוד הנתונים שנקלטו, והצגה של תוצאות עיבוד הנתונים. בכל הנוגע לחלק הראשון, בשלב זה אנו מכירים שיטה אחת לקליטת נתונים, והיא קבלתם באמצעות ההוראה input מהמשתמשת דרך ה-shell. שיטה זו מגבילה את התכניות שלנו, משני טעמים עיקריים. טעם אחד נוגע לכמות הנתונים: כל הוראת input קולטת ערך אחד מסוים (מספר, מחרוזת, רשימה וכו’). כדי לקלוט 100 ערכים יהיה עלינו לבצע הוראת input מאה פעמים. טעם נוסף נוגע למהימנות הנתונים: מהימנות זו נקבעת בין השאר לפי פעולתה של המשתמשת, ופעולה זו אינה צפויה מראש. לדוגמה אם נבקש מהמשתמשת שתכניס מספר שלם, למשל כך:
num = input(‘Please enter an integer: ‘)
נוכל לצפות שהיא תכניס מספר שלם, אך לא נוכל לדעת בוודאות שכך תעשה. ואם לא תפעל כפי שציפינו, התכנית שלנו לא תזרום לפי הרצוי.
טעמים אלה יוליכו אותנו להשתמש במקור אחר לנתונים: קבצים. קבצים יכולים להכיל ערכים רבים. אמנם גם בהם הנתונים יכולים להיות לא תקינים לגמרי. ואולם אופני הטיפול באמינות הנתונים בקבצים הם קלים ומגוונים יותר מאופני הטיפול בטעויות בנתונים המתקבלים מה-shell.
בפרק זה נעיין בטיפול בקבצי טקסט. הדיון בנושא זה יהיה תמציתי ויתמקד בשתי פעולות: קריאת כל תכנו של קובץ טקסט קיים למחרוזת, וכתיבת מחרוזת אחת בשלמותה לקובץ טקסט חדש. בנוסף נבחן פעולות נוספות במחרוזות ונדגימן אגב טיפול בנתונים שמקורם בקובץ טקסט.
(2) הנתונים - מראי מקום לפסוקי מקרא
הדגמת ההוראות שנִלמד בפרק זה תעשה בזיקה לנתונים הזהים בעיקרם לנתונים שנסמכנו עליהם בפרק הקודם, הווה אומר מראי מקום הכלולים במפתח של פסוקי מקרא המופיע בסופו של ספר אקדמי. עם זאת הפעם מקור הנתונים הללו יהיה קובץ טקסט. שמו: indLoc.txt (לחצו על השם כדי להוריד את הקובץ). בקובץ זה יש שלוש שורות. בכל שורה יש מראה מקום אחד או יותר. הנה שלוש השורות:
Gen. 15:2, 4, 8
Gen. 16:15
Lev. 1:9, 13
לכל שורה בקובץ יש רכיבים אלה:
• קיצור של שם ספר – למשל .Gen הוא קיצור של Genesis (בראשית) ו-.Lev הוא קיצור של Leviticus (ויקרא)
• תו רווח
• מספר פרק
• נקודתיים
• פסוק או פסוקים בפרק; אם יש יותר מאחד הם מופרדים זה מזה בפסיק ורווח אחד
בדוגמה כאן מופיעים מראי מקום אלה: ספר בראשית, פרק ט”ו, פסוקים ב’, ד’ וח’; ספר ויקרא, פרק א’, פסוקים ט’ וי”ג; וספר בראשית, פרק ט”ז, פסוק ט”ו.
תנו דעתכם: כשאנו מסתכלים על הקובץ בעינינו, התו האחרון בכל שורה בקובץ הוא ספרת האחדות במספר הפסוק האחרון: כלומר 8 בשורה הראשונה, 5 בשורה השנייה ו-3 בשורה השלישית. ספרת האחדות של מספר הפסוק האחרון בשורה האחרונה – כלומר הספרה 5 – היא גם התו האחרון בקובץ כולו. בהמשך הדיון נדייק את האבחנה הזאת.
להלן נראה כיצד לכתוב תכנית היוצרת, על יסוד הקובץ indLoc.txt, קובץ טקסט חדש בשם newIndLoc.txt. אך ראשית נרחיב מעט את הדיבור על קבצי טקסט ונראה כיצד קוראים מהם.
(3) מהם קבצי טקסט?
קבצי טקסט מזוהים פעמים רבות בתור קבצים שנלווית לשמותיהם הסיומת txt. דוגמה: indLoc.txt. עם זאת יש קבצים רבים שהם קבצי טקסט ויש לשמותיהם סיומות אחרות. לדוגמה הקבצים שאנו כותבים בהם תכניות בפייתון הם קבצי טקסט והסיומת של שמותיהם היא py. הסגולה המייחדת קבצי טקסט היא שהם מכילים אותיות, מספרים וסימנים שבני אדם יכולים לקרוא ובמידת מה – גם להבין. אפשר להיווכח בכך אם נפתח אותם בעורך טקסט פשוט, כגון Notepad (“פנקס רשימות”) במערכת ההפעלה Windows או TextEdit במערכת ההפעלה Mac OS X. לדוגמה נוכל להשתמש ב-Notepad כדי לפתוח את הקובץ שישמש אותנו בדיון להלן, קובץ מראי המקום indLoc.txt. כך ייראה חלון התכנה לאחר פתיחת הקובץ:

כשאנו מביטים בקובץ הטקסט כפי שהוא מוצג בתכנה אנו מסוגלים לזהות בו מילים, מספרים ותבניות. על יסוד ההסבר שהובא בסעיף הקודם תוכלו לזהות בנקל כי הקובץ מכיל רשימה של מראי מקום למקרא.
היכולת לקרוא קבצי טקסט ישירות ולהבינם, מבדילה קבצים מסוג זה מקבצים שאינם קבצי טקסט, קבצים המכונים “קבצים בינריים” (binary files). הבנת הנכתב בקובץ בינרי מחייבת את המרתו לטקסט שבני אדם יכולים לקרוא. ההמרה מתבצעת באמצעות תֹכנות מחשב. לדוגמה משפטים אלה שאתם קוראים עתה נכתבו במקורם בתכנת Microsoft Word. לו היינו פותחים את הקובץ שנכתב ב-Word ב-“פנקס רשימות”, זה מה שהיינו רואים:

אנו איננו יודעים להבין את הטקסט המוצג כאן. לעומתנו Word יודעת גם יודעת, והיא ממירה את תוכן הקובץ לטקסט שגם אנו יכולים להבין.
טיפול בקבצי טקסט בתכניות מחשב שונה מטיפול בקבצים בינריים בתכניות כאלה. כאמור כאן נתמקד בטיפול בקבצי טקסט.
(4) קריאת קובץ טקסט למחרוזת
הפעולה הראשונה שנבצע בקובץ מראי המקום indLoc.txt היא קריאת כל תכנו למחרוזת אחת. נזכיר כי תוכן הקובץ הוא זה:
Gen. 15:2, 4, 8
Lev. 1:9, 13
Gen. 16:15
ונזכיר גם כי התו האחרון בכל שורה הוא ספרת האחדות במספר הפסוק האחרון, כלומר 8, 3 ו-5.
קריאת כל תכנו של קובץ טקסט למחרוזת מתבצעת בשלושה שלבים, כדלקמן.
בשלב הראשון נפתח את הקובץ לקריאה:
f = open(‘indLoc.txt’, ‘r’)
לפנינו הוראת השמה. לכן נקרא אותה מימין לשמאל. בצדו הימני של הסימן = יש זימון של פונקציה ששמה open. פונקציה זו פותחת קובץ. כאן היא מקבלת שני ארגומנטים: מחרוזת המציינת את שם הקובץ, ומחרוזת נוספת, ‘r’. המחרוזת השנייה מציינת את סוג הטיפול המבוקש בקובץ הנפתח: המחרוזת ‘r’ (קיצור של ‘read’) פירושה כאן הוא שאנו רוצים לפתוח קובץ לקריאה. יש סוגים נוספים של פתיחת קובץ, ונראה אחד מהם בהמשך הפרק הזה. נעיר גם כי ברירת המחדל לסוג הפתיחה של קובץ היא פתיחת קובץ לקריאה, ולכן בפתיחת קובץ לקריאה באמצעות הפונקציה open אפשר להעביר רק את שם הקובץ, כך:
f = open(‘indLoc.txt’)
הפונקציה open מחזירה ערך שהוא אובייקט של קובץ. כדי לגשת לאובייקט הזה נשמור אותו במשתנה – כאן שמו הוא f (אפשר לתת לו שם אחר).
בשלב השני נקרא את תוכן הקובץ ונשמור את כל התוכן במשתנה מחרוזת אחד. נעשה זאת כך: באמצעות המשתנה f ניגש לאובייקט הקובץ ונפעיל עליו את הפונקציה read:
s = f.read()
גם זו הוראת השמה. בצִדה הימני יש זימון של הפונקציה read. הפונקציה הזאת פועלת על אובייקט של קובץ. היא אינה מקבלת ארגומנטים. היא מחזירה מחרוזת שהיא כל התוכן של הקובץ. המחרוזת הזאת מושמת כאן במשתנה s. במקרה שלפנינו המחרוזת היא זו:
‘Gen. 15:2, 4, 8\nLev. 1:9, 13\nGen. 16:15′
במחרוזת זו ההפרדה לשורות מצוינת באמצעות צירוף שני התווים n\ (לוכסן שמאלי ו-‘n’, בסדר זה). למעשה צירוף זה מייצג תו אחד (!) שהדפסתו גורמת לירידת שורה ב-shell (לדיון בתו זה ובמשפחת התווים שהוא נמנה עמה ראו להלן, סעיף 12). כך אם נדפיס את s נראה שלוש שורות ב-shell:
print(s)
>>>
Gen. 15:2, 4, 8
Lev. 1:9, 13
Gen. 16:15
בשלב השלישי והאחרון נבצע פעולה הכרחית בסופו של כל טיפול בְּקובץ: סגירתו. נסגור קובץ באמצעות הפעלת פונקציה בשם close על אובייקט הקובץ, כך:
f.close()
אם כן הקוד המלא לקריאת תוכן הקובץ indLoc בשלמותו למחרוזת הוא זה:
f = open(‘freq.txt’, ‘r’)
s = f.read()
f.close()
שלשת הוראות זו תפתח רבות מהתכניות שנכתוב מכאן ואילך. מובן ששם הקובץ הנפתח ישתנה לפי מקור הנתונים של התכנית. נספח ד’ מסביר שיטה אחרת לפתוח קובץ ועומד על החשיבות שיש לסגירת קובץ.
(5) קביעת תיקיית העבודה
כשאנו פותחים קובץ טקסט באמצעות הפונקציה open, סביבת הפיתוח שאנו עובדים בה מחפשת את הקובץ בתיקיה (folder) המוגדרת בתור “תיקיית העבודה” (working directory). על פי רוב ברירת המחדל של תיקיית העבודה היא לא התיקייה שבה נשמרים הקבצים שאנו מעוניינים לטפל בהם. לכן עלינו להגדיר במפורש את תיקיית העבודה שהקבצים בה משמשים אותנו. אפשר לעשות זאת בכמה דרכים, ונראה כאן שתי דרכים רווחות.
אפשר לציין את תיקיית העבודה כחלק מהמחרוזת המכילה את שם הקובץ ומועברת לפונקציה open. לדוגמה אם הקובץ indLoc.txt שוכן בתיקיה Python הנמצאת בכונן C, המחרוזת המציינת את שם הקובץ יכולה להיכתב כך:
f = open(r‘C:\Python\indLoc.txt’)
שימו לב לאות r המונחת לפני המחרוזת. הנחתה שם הכרחית בכתיבת המחרוזת באופן זה (כיוון שהיא מורה לפייתון שהתו לוכסן שמאלי \ אינו חלק מתו מיוחד (ראו להלן, סעיף 12). אם אין מניחים את האות r לפני המחרוזת יש להכפיל כל לוכסן שמאלי. לפי הדוגמה למעלה נצטרך לכתוב כך:
f = open(‘C:\\Python\\indLoc.txt’)
נוכל להימנע מציון התיקייה בשם הקובץ אם נגדיר מבעוד מועד את תיקיית העבודה בגוף התכנית, באמצעות שתי הוראות אלו:
import os
os.chdir(r’C:\Python’)
ההוראה הראשונה מאפשרת לנו להשתמש בכלים של מודול המכונה os (קיצור של operating system). ההוראה השנייה מגדירה את תיקיית העבודה. היא מפעילה פונקציה ששמה chdir (קיצור של change directory). הפונקציה הזאת מקבלת ארגומנט אחד: מחרוזת המציינת תיקייה במערכת הקבצים של המחשב. שימו לב שגם כאן הנחנו את האות r לפני המחרוזת.
אם הגדרנו את תיקיית העבודה באמצעות הפונקציה chdir ונרצה לטפל בקבצים בתיקיה זו – למשל לפתוח אותם לקריאה באמצעות הפונקציה read – נוכל לאחר מכן לכתוב בקצרה את המחרוזות המועברות לפונקציה open ולא לכלול בהן את המסלולים המלאים לתיקיה. למשל נוכל להעביר לפונקציה open את המחרוזת הזאת: ‘indLoc.txt’. עם זאת, אם ננקוט בשיטת הקיצור הזאת ובנקודת זמן מאוחרת יותר נרצה לטפל בקבצים שאינם נמצאים בתיקיה שהוגדרה בתור תיקיית העבודה, יהיה עלינו לשנות את תיקיית העבודה במפורש. למשל אם לאחר שטיפלנו בקובץ indLoc.txt נרצה לטפל בקובץ הנמצא בתיקיה אחרת, C:\Misc, יהיה עלינו לשוב ולזמן את הפונקציה chdir:
os.chdir(r’C:\Misc’)
שימו לב: אין צורך לכתוב שוב את ההוראה
import os
לאחר שכתבנו אותה פעם אחת.
(6) הערה על קידודים
לקראת סופו של פרק זה נראה כיצד לכתוב טקסט בקובץ טקסט. נקדים ונעיר כבר עתה כי כאשר כותבים טקסט בקובץ טקסט, הטקסט אינו נכתב כפי שהוא אלא מקודד באמצעות שיטת קידוד. למשל כתיבה של המילה Gargamel בקובץ טקסט היא למעשה כתיבת קידוד מסוים של המילה הזאת לקובץ. יש כמה שיטות קידוד בכתיבה לקובץ טקסט. אחת מהן היא ASCII, ובלי להיכנס לפרטים נאמר שהיא הפשוטה ביותר. החשוב בשעה זאת הוא זה: אם קובץ טקסט שאנו מבקשים לפתוח לקריאה (וגם לכתיבה) נכתב באמצעות שיטת קידוד שונה מ-ASCII, עלינו לציין זאת בעת פתיחת הקובץ. נעשה זאת באמצעות מחרוזת המסמלת את שיטת הקידוד. לדוגמה:
f = open(‘infile.txt’, ‘r’, encoding = ‘utf-8’)
כפי שאפשר להיווכח, בזימון הפונקציה open הוספנו ארגומנט שלישי. ארגומנט זה יוצב בפרמטר של הפונקציה open ששמו הוא encoding. הארגומנט הוא מחרוזת המציינת את שמה של שיטת הקידוד שהקובץ infile.txt נכתב בה. כאן שמה של שיטה זו היא utf-8.
מובן שכדי לציין את שיטת הקידוד עלינו לדעת מהי. אם אנו מעוניינים לקרוא קובץ טקסט ושיטת הקידוד שלו לא צוינה במקור שממנו קיבלנוהו, לא תמיד יהיה פשוט לזהותה, ולא פעם נצטרך לנחש. על כל פנים בדיונינו להלן נציין במפורש את שיטת הקידוד בקריאה מקבצים, וכן בכתיבה לקבצים. בכל הנוגע לקובץ indLoc.txt, אין צורך לציין שיטת קידוד בפתיחתו.
(7) אי אפשר לשנות מחרוזת במקום
בהתבסס על המחרוזת שקראנו מקובץ indLoc.txt, נעיין בסעיפים הבאים בכמה פעולות שכיחות במחרוזות. אך קודם שנבוא לדון בפעולות אלו עלינו להדגיש עניין חשוב הנוגע לשינוי מחרוזות, ומבדיל בין מחרוזת לסוגים אחרים של כמה אוספי ערכים בפייתון, כגון רשימות.
כפי שראינו בפרק הקודם, אפשר לשנות רשימה במקום. דוגמה:
lst = [‘no’, ‘problem’]
lst[0] = ‘NO’
ראינו כי ההוראה הראשונה מגדירה אובייקט מסוג רשימה המחזיק רשימה מסוימת:

ההוראה השנייה משנה את האובייקט lst במקום, כלומר את הרשימה שהוא מחזיק: המחרוזת הראשונה ברשימה מוחלפת במחרוזת שונה ממנה:

שינוי אובייקט במקום בלתי אפשרי באובייקטים המחזיקים מחרוזות. נעיין למשל בקוד הזה:
myS = ‘be careful!’
myS[0] = ‘B’
>>>
myS[0] = ‘B’
TypeError: ‘str’ object does not support item assignment
ההוראה הראשונה מגדירה אובייקט מסוג מחרוזת המחזיק מחרוזת מסוימת:

ההוראה השנייה מנסה לשנות תו הנמצא באינדקס מסוים במחרוזת שמחזיק האובייקט myS: התו ‘b’ באינדקס 0. פעולה כזו היא בלתי אפשרית באובייקט מחרוזת.
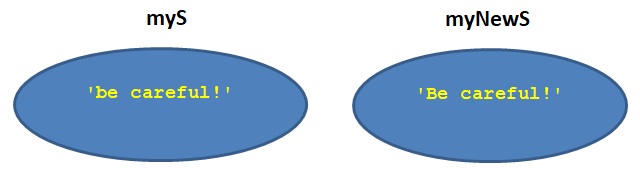
הדרך היחידה לשנות מחרוזת היא ליצור אובייקט מחרוזת חדש המבוסס על המחרוזת שיש באובייקט הקיים, למשל כך:
myS = ‘be careful!’
myNewS = ‘B’ + s[1:]
print(myNewS)
>>>
Be careful!
ההוראה השנייה בקוד זה יצרה אובייקט חדש ששמו myNewS. הוא מכיל מחרוזת המבוססת על המחרוזת שיש באובייקט myS (שאינה משתנה) ויש בה את השינוי המבוקש.
אי אפשר לשנות מחרוזת באמצעות האופרטור [ ], ואי אפשר לעשות זאת גם באמצעים אחרים. נעיין למשל בדוגמה זו להפעלת האופרטור + על מחרוזות:
s = “”
for i in range(5000):
s = s + ‘something’
קטע קוד זה מתחיל ביצירת אובייקט מחרוזת ששמו s ומכיל מחרוזת ריקה. בכל אחד מ-5000 הסיבובים של הלולאה מתבצעת ההוראה הזאת:
s = s + ‘something’
הוראה זו יוצרת אובייקט חדש המכיל את צירוף המחרוזת הזאת s למחרוזת ‘something’ (בסדר זה) ונותנת את השם s לאובייקט הזה. כך:
• לפני הלולאה נוצר אובייקט מחרוזת ראשון המכיל מחרוזת ריקה.
• בסיבוב הראשון של הלולאה נוצר אובייקט שני המכיל את המחרוזת ‘something’, והוא מכונה s.
• בסיבוב השני נוצר אובייקט שלישי המכיל את המחרוזת ‘somethingsomething’, והוא מכונה s.
• בסיבוב השלישי נוצר אובייקט רביעי המכיל את המחרוזת ‘somethingsomethingsomething’, והוא מכונה s.
וכן הלאה. לאחר יצירת כל אובייקט חדש יינתן לו השם s ולא יהיו בתכנית שמות לאובייקטים הקודמים שנוצרו.
נעיר כי בשפת פייתון מוגדרים ערכים מסוגים אחרים שאף אותם אי אפשר לשנות, ובהם מספרים. דוגמה:
a = 1
a = 2
ההוראה הראשונה יצרה אובייקט בשם a המחזיק את המספר 1.

ההוראה השנייה לא שינתה את הערך שמטפל בו האובייקט ששמו a. במקום זה היא יצרה אובייקט חדש המחזיק את המספר 2 ונתנה לו את השם a.
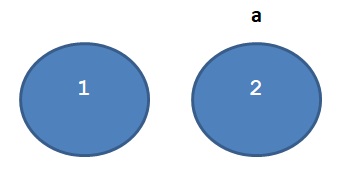
בשלב זה האובייקט המחזיק את המספר 1 קיים בזכרון המחשב, אך אין לו שם בתכנית.
לעומת מחרוזות, מספרים וסוגים נוספים של ערכים, יש בפייתון ערכים מסוגים שאפשר לשנותם (הם mutable). כאמור אחד מהם הוא רשימה. בהמשך הספר נתוודע לסוגים נוספים.
(8) האחדת ה-case של מחרוזת – הפונקציות lower ו-upper
השתמשנו בקטע קוד זה כדי לקרוא למחרוזת אחת את כל תוכן הקובץ indLoc.txt:
f = open(‘freq.txt’, ‘r’)
s = f.read()
f.close()
זו המחרוזת שהוצבה במשתנה s:
‘Gen. 15:2, 4, 8\nLev. 1:9, 13\nGen. 16:15′
בסעיף זה ובסעיפים הבאים נעבד את המחרוזת הזאת. בשלב הראשון ניצור על פיה מחרוזת חדשה שכל האותיות הפותחות את שמות הספרים בה הן “קטנות” (lower case) . כך צריכה להראות המחרוזת החדשה:
‘gen. 15:2, 4, 8\nlev. 1:9, 13\ngen. 16:15′
כיוון שבשמות הספרים רק האותיות הראשונות הן ב-upper case, וכיוון שאין במחרוזת אותיות נוספות חוץ מהאותיות שבשמות הספרים (כאמור הצירוף n\ הוא תו אחד המציין ירידת שורה), ננקוט בגישה זו: נהפוך את כל האותיות במחרוזת לקטנות. פעולה מסוג זה, כלומר האחדה של ה-case של מחרוזת – כולן ב-lower case או כולן ב-upper case – נבצעה באמצעות הפונקציות lower ו-upper. הפונקציה lower יוצרת לפי מחרוזת נתונה מחרוזת חדשה שכל התווים בה הם ב-lower case, נזמן את הפונקציה lower באמצעות אובייקט המחרוזת שברצוננו לשנות, ולא נעביר אליה ארגומנטים. דוגמה:
f = open(‘freq.txt’, ‘r’)
s = f.read()
newS = s.lower()
ההוראה השלישית בקוד הזה היא המעניינת אותנו כאן. בצִדה הימני אנו מפעילים את הפונקציה lower על המחרוזת שקראנו מהקובץ indLoc.txt. תוצאת הפעלתה היא מחרוזת חדשה שכל האותיות בה הן ב-lower case. זו המחרוזת:
‘gen. 15:2, 4, 8\nlev. 1:9, 13\ngen. 16:15′
השינוי מ-upper case ל-lower case אינו מתבצע במחרוזת s (הרי אי אפשר לשנות מחרוזת במקום), אלא מתבטא במחרוזת חדשה שהפונקציה lower יוצרת ומחזירה. למחרוזת הזאת ניתַן השם newS.
הפונקציה upper יוצרת לפי מחרוזת נתונה מחרוזת חדשה שכל התווים בה הם ב-upper case. הנה דוגמה לשימוש בה:
f = open(‘freq.txt’, ‘r’)
s = f.read()
newS = s.upper()
ההוראה השלישית יוצרת מחרוזת זו:
‘GEN. 15:2, 4, 8\nLEV. 1:9, 13\nGEN. 16:15′
במחרוזת הזאת כל האותיות הן ב-upper case.
נדגיש שוב: הפונקציות lower ו-upper אינן משנות את המחרוזת שהן פועלות עליה, אלא יוצרות מחרוזת חדשה ומחזירות אותה. לכן נשגה אם נכתוב את הקוד האחרון כך:
f = open(‘freq.txt’, ‘r’)
s = f.read()
s.upper()
לאחר ביצוע ההוראה השלישית המחרוזת במשתנה s אינה משתנה! וכיוון שלא קלטנו במשתנה את המחרוזת החדשה שיצרה הפונקציה upper – הרי אין לנו גישה למחרוזת החדשה הזאת.
(9) החלפת תת-מחרוזת - הפונקציה replace
זו המחרוזת שיש במשתנה newS לאחר הפיכת כל האותיות במחרוזת שנקלטה מהקובץ ל-lower case:
newS = ‘gen. 15:2, 4, 8\nlev. 1:9, 13\ngen. 16:15’
מטרתנו עכשיו היא לבצע כמה שינויים נוספים בהרכב התווים במחרוזת, כדלקמן:
ואלה השינויים שעלינו לבצע –
• שינוי א’ – מחיקת כל הרווחים המונחים בין קיצור שם ספר למספר פרק
• שינוי ב’ – המרת כל הנקודות לפסיקים
• שינוי ג’ – המרת כל סימני הנקודתיים לפסיקים
• שינוי ד’ – מחיקת הפסיקים בין מספרי פסוקים
לאחר ביצוע שינויים אלה תתקבל המחרוזת הזאת:
‘gen,15,2 4 8\nlev,1,9 13\ngen,16,15’
נבצע את כל השינויים הללו באמצעות הפונקציה replace.
שינויים א’ וב’ – מחיקת כל הרווחים בין קיצור שם ספר למספר פרק, והמרת כל הנקודות שבסוף קיצורי שמות הספרים לפסיקים
זו המחרוזת המוצבת במשתנה newS:
‘gen. 15:2, 4, 8\nlev. 1:9, 13\ngen. 16:15’
נרצה למחוק את כל הרווחים בין קיצור שם ספר למספר פרק, להמיר את כל הנקודות שבסוף קיצורי שמות הספרים לפסיקים, ולקבל את המחרוזת הזאת:
‘gen,15:2, 4, 8\nlev,1:9, 13\ngen,16:15’
לשם כך נחליף כל תת-מחרוזת ‘ .’ (נקודה ורווח אחד אחריה) במחרוזת ‘,’ (פסיק). כאמור נעשה זאת באמצעות הפונקציה replace. עיינו בהוראה הזאת:
newS = newS.replace(‘. ‘, ‘,’)
הפונקציה replace מחליפה מחרוזת מסוימת המופיעה במחרוזת נתונה (פעם אחת או יותר) במחרוזת אחרת. בניסוח מדויק יותר מזה: הפונקציה replace יוצרת מחרוזת חדשה המבוססת על מחרוזת נתונה; במחרוזת החדשה מוחלפת מחרוזת מסוימת המופיעה (פעם אחת או יותר) בתוך המחרוזת הנתונה, במחרוזת אחרת. ניתן לפונקציה replace שני ארגומנטים, בסדר זה: המחרוזת שיש להחליף והמחרוזת שיש להחליף בה. בזימון הפונקציה כאן קבענו שהמחרוזת שיש להחליף היא ‘ .’ והמחרוזת שיש להחליף בה היא ‘,’ . פעולת ההחלפה תיצור את המחרוזת המבוקשת:
‘gen,15:2, 4, 8\nlev,1:9, 13\ngen,16:15’
למחרוזת הזאת ניתן השם newS.
שינוי ג’ – המרת כל סימני הנקודתיים לפסיקים
בשלב זה המשתנה newS מכיל את המחרוזת הזאת:
‘gen,15:2, 4, 8\nlev,1:9, 13\ngen,16:15’
כדי להמיר את כל סימני הנקודתיים לפסיקים, נשתמש שוב בפונקציה replace, כך:
newS = newS.replace(‘:’, ‘,’)
הוראה זו קבעה כי המחרוזת שיש להחליף היא ‘:’ והמחרוזת שיש להחליף בה היא ‘,’ . פעולת ההחלפה תיצור את המחרוזת הזאת:
‘gen,15,2, 4, 8\nlev,1,9, 13\ngen,16,15’
הקוד נותן את השם newS למחרוזת הזאת.
לדיון נוסף בהחלפת תווים במחרוזות (ספציפית: במטרה להשמיט רווחים מהמחרוזת), ראו נספח ה’.
שינוי ד’ – הסרת הרווחים בין מספרי פסוקים והנחת תו רווח יחיד ביניהם
לאחר פעולת ההחלפה האחרונה המשתנה newS מכיל את המחרוזת הזאת:
newS = ‘gen,15,2, 4, 8\nlev,1,9, 13\ngen,16,15’
כפי שאפשר לראות במחרוזת זו יש רווחים רק בין פסיקים למספרי פסוקים. אם כן כדי לבצע את השינוי הרביעי והאחרון, נוכל להמיר בתו רווח יחיד כל פסיק שאחריו תו רווח, כך:
newS = newS.replace(‘, ‘, ‘ ‘)
לפי הוראה זו כל מחרוזת ‘ ,’ (פסיק ורווח יחיד אחריו) תוחלף במחרוזת ‘ ‘ (רווח יחיד). פעולת ההחלפה תיצור את המחרוזת הזאת:
‘gen,15,2 4 8\nlev,1,9 13\ngen,16,15’
זו בדיוק המחרוזת שרצינו ליצור. ההוראה האחרונה בקוד נותנת לה את השם newS.
(10) פיצול מחרוזת לרשימה וצירוף מחרוזות ברשימה – הפונקציות split ו-join
קראנו את כל תוכן הקובץ indLoc.txt לתוך משתנה מחרוזת. אחר כך הפכנו את כל המחרוזת ל-lower case ושינינו את הרכב התווים בה – בייחוד התווים המפרידים בין קיצורי שמות הספרים, מספרי הפרקים ומספרי הפסוקים. בשלב זה המחרוזת שאנו מטפלים בה היא זו:
newS = ‘gen,15,2 4 8\nlev,1,9 13\ngen,16,15‘
מחרוזת זו מכילה מראי מקום לפסוקים בשלושה ספרי מקרא – הפסוקים בכל ספר באים בשורה נפרדת. השלב הבא בעיבוד המחרוזת הוא שינוי סדר הופעת שלוש השורות: נמיין אותן בסדר לא יורד לפי שמות הספרים. ראשית נציג את האלגוריתם שננקוט בו ולאחר מכן נראה כיצד לממש אלגוריתם זה. לאלגוריתם שלושה שלבים, כדלקמן:
(1) תחילה נפצל את המחרוזת לרשימה של מחרוזות. נשתמש בצירוף n\ בתור תו מפצל באופן שברשימה החדשה יהיו שלוש מחרוזות אלו:
[‘gen,15,2 4 8‘, ‘lev,1,9 13‘, ‘gen,16,15‘]
(2) אחר כך נמיין את המחרוזות בתוך הרשימה שיצרנו בסדר לא יורד לפי שמות הספרים:
[‘gen,15,2 4 8‘, ‘gen,16,15‘, ‘lev,1,9 13‘]
שתי המחרוזות הראשונות מתחילות ב-‘gen,1’, אך הראשונה נמשכת ב-‘5’, ואילו השנייה ממשיכה ב-‘6’, המחרוזת ‘5’ היא קטנה מהמחרוזת ‘6’ ומכאן נובע הסידור שלהן ברשימה.
(3) לבסוף נצרף זו לזו את המחרוזות ברשימה הממוינת, לפי סדר הופעתן בה, ובין כל שתי מחרוזות נניח את המחרוזת ‘n\’. נקבל מחרוזת אחת זו:
newS = ‘gen,15,2 4 8\ngen,16,15\nlev,1,9 13‘
עתה נראה כיצד לממש את האלגוריתם. נפתח בפיצול המחרוזת newS לרשימה של מחרוזות. כדי לפצל מחרוזת לרשימה לפי תו מפצל נשתמש בפונקציה split. להלן הקוד.
newS = ‘gen,15,2 4 8\nlev,1,9 13\ngen,16,15’
lines = newS.split(‘\n’)
print(lines)
>>>
[‘gen,15,2 4 8’, ‘lev,1,9 13’, ‘gen,16,15’]
ההוראה השניה בקוד היא הוראת השמה. בצִדה הימני מזומנת הפונקציה split באמצעות אובייקט המחרוזת newS: כתבנו את שמו, newS, אחר כך נקודה, ואחר כך את זימון הפונקציה split. נתַנו ארגומנט אחד לפונקציה split: המחרוזת ‘n\’. כזכור זו המחרוזת המפרידה בין שורות בקובץ indLoc.txt. כאן השתמשנו בצירוף הזה (לוכסן שמאלי ו-n) בתור מחרוזת פיצול. לפי מחרוזת זו הפונקציה split מפצלת את המחרוזת שיש במשתנה newS לשלוש מחרוזות; מחרוזת הפיצול אינה נמנית עמן. שלוש המחרוזות מוכנסות לתוך רשימה, והפונקציה מחזירה רשימה זו. הקוד נותן את השם lines לרשימה.
שימו לב: בתור מחרוזת פיצול אפשר להעביר לפונקציה split מחרוזות שונות מ-‘n\’. למשל זו הרשימה שתתקבל אם ניתן לפונקציה split את המחרוזת ‘lev’ בתור מחרוזת פיצול:
newS = ‘gen,15,2 4 8\nlev,1,9 13\ngen,16,15’
lines = newS.split(‘lev’)
print(lines)
>>>
[‘gen,15,2 4 8\n’, ‘,1,9 13\ngen,16,15’]
ברשימה שנוצרה זו יש שתי מחרוזות: אחת כוללת את כל התווים המופיעים עד למחרוזת ‘lev’ במחרוזת המוצבת במשתנה newS, והאחרת כוללת את כל התווים המופיעים לאחר המחרוזת ‘lev’ במחרוזת המוצבת במשתנה newS.
אפשר גם לזמן את הפונקציה split ללא ארגומנט כלל. במקרה זה הפיצול הוא לפי תווי רווח כלשהם (white spaces: רווח, טאב, ותו ירידת שורה, כלומר ‘n\’). דוגמה:
newS = ‘gen,15,2 4 8 \nlev,1,9 13\ngen,16,15’
lines = newS.split()
print(lines)
>>>
[‘gen,15,2’, ‘4’, ‘8’, ‘lev,1,9′, ’13’, ‘gen,16,15’]
הפיצול לפי תו רווח כלשהו אינו מתאים במקרה שלפנינו, כיוון הוא גורם להפרדת מראי מקום שיש בהם יותר ממספר פסוק אחד למרכיביהם. למשל כאן מראה המקום הראשון פוצל לשלוש מחרוזות (הראשונות ברשימה).
אם כן עכשיו יש בידינו רשימה המכילה שלוש מחרוזות – כל אחת מכילה מראי מקום לפסוקים בספר אחד:
[‘gen,15,2 4 8’, ‘lev,1,9 13’, ‘gen,16,15’]
עתה ברצוננו למיין את הרשימה הזאת בסדר לא יורד לפי שמות הספרים. אנו יודעים כיצד למיין רשימה – באמצעות הפונקציה sort או באמצעות הפונקציה sorted. כאן נשתמש בפונקציה sorted:
newS = ‘gen,15,2 4 8\nlev,1,9 13\ngen,16,15’
lines = newS.split(‘\n’)
lines = sorted(lines)
print(lines)
>>>
[‘gen,15,2 4 8’, ‘gen,16,15’, ‘lev,1,9 13’]
כזכור הפונקציה sorted מקבלת רשימה, אינה משנה אותה, ומחזירה רשימה חדשה שיש בה את הערכים ברשימה המקורית, ממוינים. כאן המיון הוא בסדר לא-יורד, לפי הנדרש. גם תנו דעתכם ששני מראי המקום הראשונים ממוינים כראוי על אף ששניהם מתחילים בחמישה תווים שווים (‘gen,1’).
עכשיו המשתנה lines מכיל רשימה ממוינת של מחרוזות מראי המקום:
lines = [‘gen,15,2 4 8’, ‘gen,16,15’, ‘lev,1,9 13’]
בשלב הבא והאחרון נצרף זו לזו את המחרוזות ברשימה lines. נוכל לעשות זאת באמצעות האופרטור [ ] – לשם גישה למחרוזות ברשימה lines – ובאופרטור + – לשם צירוף מחרוזות. וכך נכתוב:
newS = lines[0] + ‘\n’ + lines[1] + ‘\n’ + lines[2]
print(newS)
>>>
‘gen,15,2 4 8 \nlev,1,9 13\ngen,16,15’
שימו לב: כאשר פיצלנו את המחרוזת המקורית באמצעות הפונקציה split, פיצלנו אותה לפי המחרוזת ‘n\’. לכן המחרוזת הזאת לא הופיעה בתוך המחרוזות ברשימה lines. עתה כשבאנו ליצור מחרוזת חדשה מהמחרוזות ברשימה lines, שמנו את הצירוף ‘n\’ בין המחרוזות האלה כדי שהמחרוזת המתקבלת תהיה בדיוק בהרכב המקורי שלה – מחרוזות המופרדות זו מזו באמצעות המחרוזת ‘n\’.
דרך אחרת ונוחה יותר מזו לצירוף מחרוזות ברשימה למחרוזת אחת ולהנחת מחרוזת בין המחרוזות המצורפות היא שימוש בפונקציה join. כך נשתמש בה במקרה דנן:
connectingString = ‘\n’
newS = connectingString.join(lines)
print(newS)
>>>
‘gen,15,2 4 8 \ngen,16,15\nlev,1,9 13’
מקדו מבטכם בזימון הפונקציה join בהוראה השנייה בקוד. הפונקציה join מקבלת רשימה של מחרוזות – כאן רשימה של שלוש מחרוזות מראי המקום. הפונקציה מזומנת באמצעות אובייקט מחרוזת – כאן שמו הוא connectingString. אובייקט זה מחזיק את המחרוזת שתונח בין המחרוזות המצורפות – כאן המחרוזת הזאת היא ‘n\’. הפונקציה join מחזירה מחרוזת אחת שהיא צירוף של כל המחרוזות ברשימה שהיא מקבלת ובין המחרוזות האלה מונחת מחרוזת הצירוף. המחרוזת שהוחזרה היא בדיוק המחרוזת שרצינו ליצור.
נעיר כי בקוד כאן שמרנו את מחרוזת הצירוף, ‘n\’ בתוך משתנה וזימנו את הפונקציה join באמצעות המשתנה-האובייקט הזה, כך:
connectingString.join(lines)
למעשה אין צורך לשמור את מחרוזת הצירוף במשתנה ומקובל לכתוב אותה במפורש, כך:
‘\n’.join(lines)
אין הבדל בין הקוד הזה לקודמו חוץ מהכתיבה המפורשת של המחרוזת המשמשת בצירוף המחרוזות זו לזו.
(11) יצירת קובץ טקסט וכתיבה בו
בנקודה זו סיימנו לעבד את המחרוזת שקראנו מתוך הקובץ indLoc.txt, ובמצבה הנוכחי היא נראית כך:
newS = ‘gen,15,2 4 8 \ngen,16,15\nlev,1,9 13’
עתה אנו רוצים לכתוב את המחרוזת הזאת לקובץ טקסט חדש: newIndLoc.txt . על אף שכתיבה לקובץ טקסט היא כביכול פעולה ‘הפוכה’ לקריאת תכנו של קובץ, הרי מצד הקוד יש הרבה מן המשותף בין שתי הפעולות. הבאנו כאן השוואה בין הקוד הקורא את תוכן הקובץ indLoc.txt לבין הקוד היוצר קובץ חדש בשם newIndLoc.txt וכותב בו מחרוזת. החלקים השווים מסומנים בכחול ואילו החלקים שאינם שווים מסומנים באדום.

כמו קריאה מקובץ גם כתיבה לקובץ מתחילה בזימון הפונקציה open, וגם בזימונה כאן הפונקציה הזאת מקבלת שם של קובץ. אמנם הפעם הארגומנט השני אינו ‘r’ אלא ‘w’ (קיצור של write). בהקשר הנוכחי המחרוזת ‘w’ מציינת שאנו רוצים לפתוח קובץ לשם כתיבה בו. כפי שכבר ראינו הפונקציה open מחזירה אובייקט המאפשר לנו גישה לתוכן הקובץ, ושמו של האובייקט הזה הוא f. ההוראה השנייה בכתיבה לקובץ מזמנת את הפונקציה write באמצעות האובייקט f. הפונקציה מקבלת ארגומנט אחד: מחרוזת שיש לכתוב בקובץ. לסיום, גם כאן ההוראה השלישית סוגרת את הקובץ.
נעיר שתי הערות נוספות הנוגעות לכתיבה לקובץ טקסט באמצעות הקוד שתואר. ראשית הקובץ החדש נוצר בתיקיה שהוגדרה בתור תיקיית העבודה. שנית אם הפונקציה open מקבלת בתור ארגומנט שני את המחרוזת ‘w’, כלומר היא באה לפתוח קובץ חדש לכתיבה, ואם בתיקיית העבודה כבר קיים קובץ בשם שניתן בתור ארגומנט לפונקציה open, התוכן של הקובץ הקיים נמחק. לדוגמה אם קודם לזימון הפונקציה write כבר התקיים בתיקיית העבודה קובץ בשם newIndLoc.txt, העברת שמו לזימון של הפונקציה write תגרום למחיקת תכנו.
(12) תווים מיוחדים
לפני שנחתום את הדיון מן הראוי להעיר בקצרה בדבר סוגיה שנגענו בה בעקיפין בסעיפים הקודמים. ראינו כי בקביעת תיקיית העבודה באמצעות הפונקציה chdir, אם אין כותבים את האות r לפני המחרוזת המציינת את תיקיית העבודה, יש להכפיל את הלוכסנים השמאליים, כך:
os.chdir(‘C:\\Python’)
רק כך פייתון מבינה כי המחרוזת ‘\\’ מציינת לוכסן שמאלי. גם נדרשנו פעמים רבות לצירוף ‘n\’ וראינו כי הוא מייצג ירידת שורה.
הצירופים ‘\\’ ו-‘n\’ משתייכים לקבוצה מיוחדת של מחרוזות המוגדרת בפייתון. המחרוזות בקבוצה מכונות בלעז escape characters. כל אחת מהן היא צירוף של לוכסן שמאלי (backslash) ותו אחד אחר. נכנה מחרוזות אלו בשם (המטעה במידת מה) ‘תווים מיוחדים’. על פי רוב אין מדפיסים תווים מיוחדים כשלעצמם אלא משלבים אותם בתור מחרוזות אחרות. הנה דוגמה לשימוש בתו מיוחד נוסף – ‘t\’, התו טאב, רווח ארוך:
print(‘ID\tNAME\tAGE’)
>>>
ID NAME AGE
לרשימה מלאה של תווים מיוחדים בפייתון ראו כאן (סעיף 2.4.1).
(13) סיכום
בפרק זה העשרנו את ארגז הכלים העומד לרשותנו בטיפול במחרוזות. בנוסף למדנו כיצד לקרוא טקסט מקבצי טקסט וכיצד לכתוב בהם. קניית היכולת לקרוא מקבצי טקסט היא כמו החלפת לוח צבעים (פְּתֵכָה) שיש בו מספר קטן של צבעים, בלוח שיש בו מספר עצום של צבעים וגוונים. יכולת זו תאפשר לנו לטפל בכמויות גדולות יותר של נתונים מהכמויות שיכולנו לטפל בהן עד עתה. בה בעת היא תגדיל את גיוונן של התכניות שאנו כותבים ואת עושרן, בין השאר מבחינת הטיפול באוספים. בשני הפרקים הבאים נכיר שלושה סוגים של אוספים שטרם הכרנו: קבוצה, רשומה ומילון, ונדגים כיצד לשמור בהם נתונים שמקורם בקבצים.