בעיה י"ג

הוראות המופיעות בגוף של מבנה while ומתבצעות כל עוד תנאי הלולאה מתקיים צריכות להיות מוזזות ימינה ביחס לשורה הראשונה במבנה. הקוד התקין:
age = input(‘Insert age; -1 to stop: ‘)
while age != ‘-1’:
print(age)
age = input(‘Insert age; -1 to stop: ‘)
לבעיה זו שלושה סעיפים. כולם מטפלים במילון המייצג גליון נתונים במבנה זה –
FILENAME WORD FREQ
0 text1 only 4
1 text1 across 1
2 text2 joke 1
3 text2 only 1
4 text2 falling 1
5 text3 bad 1
6 text3 beat 1
7 text4 only 2
8 text5 already 2
9 text5 most 3
10 text6 flying 1
בגליון שלושה משתנים (עמודות): FILENAME, WORD ו-FREQ, ומספר כלשהו של תצפיות (שורות). בכל תצפית שמור מידע על אודות השכיחות של מילה אחת בקובץ טקסט מסוים. לדוגמה לפי התצפית הראשונה המילה only מופיעה 4 פעמים בקובץ text1. המספרים בשול השמאלי של הגליון הם אינדקסים של תצפיות. לשורת שמות המשתנים אין אינדקס.
במילון השומר את המידע בגליון הנתונים יש שלושה זוגות. בכל זוג המפתח הוא שם משתנה בגליון הנתונים, והערך הוא רשימה המכילה את הנתונים במשתנה זה. למשל הנה מילון בשם freqDict המחזיק את הנתונים בגליון המופיע למעלה –
freqDict =
{‘FILENAME’: [‘text1′,’text1′,’text2′,’text2′,’text2’, ‘text3′,’text3′,’text4′,’text5′,’text5′,’text6’],
‘WORD’: [‘only’,’across’,’joke’,’only’,’falling’,’bad’,’beat’,’only’,’already’, ‘most’,’flying’],
‘FREQ’: [‘4’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘2’, ‘2’, ‘3’, ‘1’]}
אורכיהן של הרשימות (הערכים) במילון שווים. בנוסף הערכים בכל הרשימות, כולל ברשימה שהמפתח ‘FREQ’ ממופה אליה, הם מחרוזות.
(א) כתבו את הפונקציה tableByInds –
tableByInds(table, inds)
לפונקציה שני פרמטרים אלה –
– table –מילון השומר גליון נתונים, בתבנית שתוארה למעלה
– inds – רשימת אינדקסים של תצפיות בגליון
הפונקציה יוצרת מילון הבנוי לפי תבנית המילון table ומכיל רק את המידע בתצפיות שהאינדקסים שלהן מופיעים ברשימה inds. הפונקציה מחזירה את המילון שיצרה. לדוגמה עבור המילון freqDict שהוגדר למעלה הזימון הזה –
tableByInds(freqDict, [2, 3, 5])
יחזיר את המילון הזה –
{‘FILENAME’: [‘text2’, ‘text2’, ‘text3’],
‘WORD’: [‘joke’, ‘only’, ‘bad’],
‘FREQ’: [‘1’, ‘1’, ‘1’]}
ובתצוגת גליון נתונים –
FILENAME WORD FREQ
0 text2 joke 1
1 text2 only 1
2 text3 bad 1
(ב) כתבו את הפונקציה filterTable –
filterTable(table, colName, values)
לפונקציה שלושה פרמטרים אלה –
– table – מילון השומר גליון נתונים, בתבנית שתוארה למעלה
– colName – שם משתנה ב-table
– values – רשימה של ערכים היכולים להופיע במשתנה colName בגליון הנתונים table
הפונקציה בונה מילון הבנוי לפי תבנית המילון table ומכיל רק את המידע בתצפיות שבהן המשתנה colName בגליון table מכיל ערך הנמצא ברשימה values. הפונקציה מחזירה את המילון שיצרה. לדוגמה עבור המילון freqDict שהוגדר למעלה הזימון הזה –
filterTable(freqDict, ‘WORD’, [‘only’, ‘joke’])
יחזיר את המילון הזה –
{‘FILENAME’: [‘text1’, ‘text2’, ‘text2’, ‘text4’],
‘WORD’: [‘only’, ‘joke’, ‘only’, ‘only’],
‘FREQ’: [‘4’, ‘1’, ‘1’, ‘2’]}
ובתצוגת גליון נתונים –
FILENAME WORD FREQ
0 text1 only 4
1 text2 joke 1
2 text2 only 1
3 text4 only 2
בגליון זה ובמילון השומר את הנתונים בו יש אך ורק תצפיות שבהן במשתנה WORD בגליון table מופיעה המילה only או המילה joke.
(ג) כתבו את הפונקציה sortTable –
sortTable(table, colName, rev = False)
לפונקציה שלושה פרמטרים אלה –
– table – מילון השומר גליון נתונים, בתבנית שתוארה למעלה
– colName – שם משתנה ב-table
– rev – ערך בוליאני; ערך בררת מחדל הוא False
הפונקציה בונה מילון הבנוי לפי תבנית המילון table. במילון החדש התצפיות ממוינות לפי הערכים במשתנה colName. אם rev מקבל True המיון הוא בסדר מילוני יורד; אם rev הוא False המיון הוא בסדר מילוני עולה. הפונקציה מחזירה את המילון שיצרה.
דוגמה: הזימון הזה –
sortTable(freqDict, “FREQ”, False)
או לחילופין הזימון השקול הזה –
sortTable(freqDict, “FREQ”)
מחזירים שניהם מילון חדש המבוסס על המילון table וממוין בסדר עולה לפי העמודה FREQ. זה תוכן המילון –
{‘FILENAME’: [‘text1’, ‘text2’, ‘text2’, ‘text2’, ‘text3’, ‘text3′,’text6’, ‘text4’, ‘text5’, ‘text5’, ‘text1’],
‘WORD’: [‘across’, ‘joke’, ‘only’, ‘falling’, ‘bad’, ‘beat’, ‘flying’, ‘only’, ‘already’, ‘most’, ‘only’],
‘FREQ’: [‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘2’, ‘2’, ‘3’, ‘4’]}
ובתבנית טבלה –
FILENAME WORD FREQ
0 text1 across 1
1 text2 joke 1
2 text2 only 1
3 text2 falling 1
4 text3 bad 1
5 text3 beat 1
6 text6 flying 1
7 text4 only 2
8 text5 already 2
9 text5 most 3
10 text1 only 4
גליון נתונים זה ממוין בסדר עולה לפי המשתנה FREQ.
לפתרון בקוד ראו כאן.
פתרון מפורט
(א) כל הסעיפים בבעיה זו עוסקים בפעילות רווחת בתכניות מחשב: טיפול בגליונות נתונים. בפייתון יש ספריות ייעודיות לטיפול בגליונות נתונים, כגון pandas. ואולם נוכל בהחלט לשמור גליונות נתונים ולטפל בהם ללא שימוש בספריות אלו. אפשר לשמור את הגליונות באופנים מגוונים, כגון ברשימה של רשימות, או במילון כפי שתואר למעלה. מטבע הדברים במבני נתונים אלה האוספים השומרים את הערכים במשתני הגליון יהיו באורכים שווים (למשל רשימת המילים שווה באורכה לרשימת השכיחויות). הטיפול במבנה השומר את הגליונות מחייב שליטה בכמה מיומנויות חשובות, ובייחוד סריקת אינדקסים. כך הדבר בשאלה הנשאלת בסעיף זה.
הפרמטר לפונקציה tableByInds הוא מילון המייצג גליון נתונים, לדוגמה –
table = {‘FILENAME’: [‘text1′,’text1′,’text2′,’text2′,’text2′,’text3′,’text3′,’text4′,’text5′,’text5′,’text6’],
‘WORD’: [‘only’,’across’,’joke’,’only’,’falling’,’bad’,’beat’,’only’,’already’, ‘most’,’flying’],
‘FREQ’: [‘4’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘2’, ‘2’, ‘3’, ‘1’]}
והפרמטר inds הוא רשימת אינדקסים, לדוגמה –
inds = [2, 3, 5]
עלינו לאסוף את הערכים הנמצאים בשלושת אינדקסים אלה בכל אחת ואחת מהרשימות שאליהן ממופים מפתחות המילון, ולהשתמש בנתונים שנאספו לצורך בניית מילון חדש זה –
{‘FILENAME’: [‘text2’, ‘text2’, ‘text3’],
‘WORD’: [‘joke’, ‘only’, ‘bad’],
‘FREQ’: [‘1’, ‘1’, ‘1’]}
נעיין למשל ביצירת הזוג הזה במילון החדש –
‘FILENAME’: [‘text2’, ‘text2’, ‘text3’]
ניצור אותו בלולאה אגב סריקה של הערכים ברשימה inds. נתחיל ביצירת אוסף ריק – כאן: רשימה ריקה, זו שאליה ימופה המפתח ‘FILENAME’ במילון החדש. לאחר מכן, נסרוק את הערכים ברשימה inds. נשתמש בכל ערך נסרק בתור אינדקס לרשימה שאליה ממופה המפתח ‘FILENAME’ במילון המקורי table (מבחינה זו יש כאן גישה זהה לזו שנקטנו בה בפתרון לבעיה י’). נוסיף את הערך המופיע באינדקס זה לרשימה שאליה ממופה המפתח ‘FILENAME’ במילון החדש. הקוד יכול להראות כך –
d = {}
d[‘FILENAME’] = []
for ind in inds:
d[‘FILENAME’].append(table[‘FILENAME’][ind])
שתי נקודות ראויות לתשובת לב בקוד זה. ראשית שימו לב להפעלה הכפולה של האופרטור [ ] בשורה האחרונה. ההפעלה הראשונה (השמאלית) היא על מילון: בין הסוגריים המרובעים הנחנו שם של מפתח, ‘FILENAME’, והוחזרה הרשימה שאליה ממופה מפתח זה במילון המקורי table. ההפעלה השניה היא על הרשימה הזאת: בין הסוגריים המרובעים הנחנו אינדקס, הוחזר הערך הנמצא באינדקס זה ברשימה, והפונקציה append הוסיפה אותו לסוף הרשימה שאליה ממופה המפתח ‘FILENAME’ במילון החדש ההולך ונבנה כאן. נקודה חשובה נוספת היא שקוד זה ערוך לפי התבנית המוכרת של יצירת אוסף חדש אגב סריקה של אוסף נתון (ראו בעיה א’). אפשר לכתוב את הקוד הזה בקיצור באמצעות List Comprehension, כך –
d = {}
d[‘FILENAME’] = [table[‘FILENAME’][ind] for ind in inds]
מובן כי אין די ביצירת רשימה עבור מפתח אחד. כדי ליצור את המילון החדש כולו, בתוך הפונקציה tableByInds יש לשלב את הקוד המוצג למעלה בלולאה שתפעיל אותו ליצירת הרשימות שאליהם ממופים כל אחד ואחד מהמפתחות. הנה הקוד המלא של הפונקציה –
def tableByInds(table, inds):
filteredDict = {}
for key, values in table.items():
filteredDict[key] = []
for ind in inds:
filteredDict[key].append(values[ind])
return filteredDict
בתוך הפונקציה קוננה הלולאה שכתבנו למעלה בתוך לולאה חיצונית הסורקת את כל זוגות המילון המקורי table. בכל סיבוב וסיבוב של הלולאה החיצונית key מחזיק מפתח במילון המקורי table, כלומר שם של משתנה בגליון הנתונים (‘FILENAME’, ‘WORD’, ו-‘FREQ’), ו-values מכיל את הרשימה שאליה ממופה מפתח זה. לפני ביצוע הלולאה הפנימית מוכנס זוג חדש למילון: המפתח בו הוא שם המשתנה הנסרק הנוכחי והערך שהוא ממופה אליו הוא רשימה ריקה. בתוך הלולאה הפנימית אנו משתמשים ב- values– כאמור רשימה שאליה ממופה במילון המקורי המפתח שהוכנס זה עתה למילון – נוטלים מרשימה זו אחד אחר האחר את כל הערכים הנמצאים באינדקסים המופיעים ברשימה inds, ומוסיפים אותם לרשימה הולכת ונבנית, זו שאליה ימופה המפתח הנסרק הנוכחי במילון החדש. גם כאן אפשר לקצר את הקוד הבונה את הרשימה שאליה ממופה כל מפתח באמצעות List Comprehension, כך –
def tableByInds(table, inds):
filteredDict = {}
for key, values in table.items():
filteredDict[key] = [values[ind] for ind in inds]
return filteredDict
לפני שנעבור לדון בסעיפיה הבאים של הבעיה נסב את תשומת הלב לאבחנה זו: המימוש של הפונקציה tableByInds אינו מחייב שהאינדקסים ברשימה inds יופיעו לפי סדר התצפיות בגליון הנתונים המקורי, כלומר בסדר עולה. למשל אם נעביר לפונקציה את רשימת האינדקסים [5, 2, 3], כלומר קודם 5, אחר כך 2, ולבסוף 3, ונזמן את הפונקציה כך –
tableByInds(freqDict, [5, 2, 3])
הפונקציה תפעל באופן תקין, ותחזיר את המילון הזה –
{‘FILENAME’: [‘text3’, ‘text2’, ‘text2’],
‘WORD’: [‘bad’, ‘joke’, ‘only’],
‘FREQ’: [‘1’, ‘1’, ‘1’]}
ובתצוגת גליון נתונים –
FILENAME WORD FREQ
0 text3 bad 1
1 text2 joke 1
2 text2 only 1
כאן מופיעה ראשית התצפית שבגליון המקורי האינדקס שלה הוא 5, מיד מתחתיה התצפית שבגליון המקורי האינדקס שלה הוא 2, ולבסוף התצפית שבגליון המקורי האינדקס שלה הוא 3.
(ב) הבעיה המוצגת בסעיף זה דומה לזו המוצגת בסעיף הקודם. גם כאן אנחנו נדרשים ליצור מילון שיש בו תצפיות מסוימות המופיעות במילון הנתון. אולם הפעם הבחירה של התצפיות אינה לפי אינדקסים של תצפיות אלא לפי רשימת ערכים המועברת לפרמטר values: המילון החדש צריך להכיל את כל התצפיות שבהן בעמודה מסוימת, זו ששמה מועבר לפרמטר colName (כלומר ‘FILENAME’, ‘WORD’, או ‘FREQ’), נמצא ערך כלשהו המופיע ברשימה values. במחשבה ראשונה אולי נרצה לכתוב פתרון המבוסס על גישה לאינדקסים זהים ברשימות שוות אורך. נעיין למשל בגליון הזה –
FILENAME WORD FREQ
0 text1 across 1
1 text2 joke 1
2 text2 only 1
3 text2 falling 1
4 text3 bad 1
5 text3 beat 1
6 text6 flying 1
7 text4 only 2
8 text5 already 2
9 text5 most 3
10 text1 only 4
נניח כי עלינו להוסיף למילון החדש אך ורק את התצפיות שבהן בעמודה WORD מופיעה המילה only או המילה joke. אם למשל נדע את האינדקס שבו נמצאת המילה joke בעמודה WORD, כלומר 1, יהיה בידינו מידע מספיק לאיסוף כל הערכים הנמצאים בתצפית שהאינדקס שלה הוא 1: כל שיהיה עלינו לעשות הוא לעבור משתנה-משתנה, ולאסוף את הערך הנמצא בתצפית שהאינדקס שלה 1. במהלך זה אנו מתבססים על היות כל העמודות שוות אורך, ועל הזיקה שיש בין הערכים הנמצאים בהם בכל אינדקס ואינדקס. מכאן נובע ועולה אלגוריתם שעליו נוכל להסמיך את הפתרון, והוא זה –
(1) נכניס למילון החדש שלושה זוגות: בכל אחד המפתח יהיה שם עמודה (כלומר ‘FILENAME’, ‘WORD’, או ‘FREQ’) והערך יהיה רשימה ריקה.
(2) נסרוק את האינדקסים ברשימה שאליה ממופה המשתנה colName בגליון המקורי table, ועבור כל אינדקס –
(2.1) אם הערך המופיע באינדקס זה ברשימה הוא אחד מהערכים שיש ברשימה values
(2.2) נוסיף לכל אחת מהרשימות במילון החדש ההולך ונבנה, את הערך הנמצא
באינדקס זה ברשימה המתאימה מהמילון המקורי table (למשל לרשימה שאליה
ממופה המפתח ‘FILENAME’ במילון החדש נוסיף את הערך שנמצא באינדקס זה
ברשימה שאליה ממופה המפתח ‘FILENAME’ במילון המקורי table)
הנה הצעה למימוש האלגוריתם –
def filterTable(table, colName, values):
# 1
d = {}
for k in table:
d[k] = []
# 2
for i in range(len(table[colName])):
# 2.1
if table[colName][i] in values:
# 2.2
for k in d:
d[k].append(table[k][i])
return d
נדגיש שוב – כשאנו נכנסים ללולאה הפנימית יש בידינו אינדקס לרשימה שאליה ממופה המפתח colName במילון המקורי (לדוגמה אינדקס 1 ברשימה שאליה ממופה המפתח ‘WORD’ ב-table); ברשימה זו ובאינדקס זה יש ערך המופיע ברשימה values (למשל ‘only’; וידאנו זאת בצעד 2.1). והעיקר: אנחנו יכולים לדעת כי הערכים באינדקס זה בכל הרשימות שאליהן ממופים המפתחות במילון המקורי table יוצרים תצפית אחת (למשל הערכים באינדקס 1 בשלוש הרשימות שאליהם ממופים מפתחות המילון table יוצרים תצפית אחת בגליון).
נעיין בגישה נוספת לפתרון. בפתרון לסעיף א’ כתבנו את הפונקציה tableByInds. פונקציה זו יוצרת מילון המורכב מכל התצפיות שהאינדקסים שלהן נתונים. נוכל להשתמש בפונקציה זו בכתיבת הפונקציה filterTable. כדי להבין כיצד נעיין שוב בגליון הדוגמה –
FILENAME WORD FREQ
0 text1 across 1
1 text2 joke 1
2 text2 only 1
3 text2 falling 1
4 text3 bad 1
5 text3 beat 1
6 text6 flying 1
7 text4 only 2
8 text5 already 2
9 text5 most 3
10 text1 only 4
גם הפעם נניח כי עלינו להוסיף למילון החדש אך ורק את התצפיות שבהן בעמודה WORD מופיעה המילה only או המילה joke. אם נכין רשימה של אינדקסים של הערכים בעמודה WORD שבהם נמצאות שתי המילים הללו, כלומר –
[1, 2, 7, 10]
כל שיהיה עלינו לעשות הוא להעביר רשימת אינדקסים זו לפונקציה tableByInds והיא תיצור את המילון המבוקש. הנה הצעה למימוש הפונקציה filterTable לפי גישה זו –
def filterTable(table, colName, values):
inds = []
for ind in range(len(table[colName])):
if table[colName][ind] in values:
inds.append(ind)
return tableByInds(table, inds)
הלולאה סורקת את האינדקסים של הרשימה שאליה ממופה המפתח colName במילון המקורי table. עבור כל אינדקס מתבצעת בדיקה: אם באינדקס זה יש ברשימה ערך המופיע ברשימה values, האינדקס מיתוסף לסוף רשימת אינדקסים הולכת ונבנית. השורה האחרונה בקוד מעבירה את רשימת האינדקסים לפונקציה tableByInds, מקבלת את המילון המבוקש, ומחזירה אותו.
אם נמיר את הלולאה לביטוי List Comprehension נוכל לכתוב את כל גוף הפונקציה בשורה אחת בלבד, כך (השורה היחידה נפרשת כאן על שתי שורות מאילוצי מקום) –
def filterTable(table, colName, values):
return tableByInds(table, [ind for ind in range(len(table[colName])) if table[colName][ind] in values])
sortTable(freqDict, ‘WORD’)
המיון כאן יהיה לפי העמודה WORD ובסדר עולה (לא העברנו ארגומנט לפרמטר rev ולכן הפונקציה תשתמש בערך בררת המחדל שלו, False, המציין מיון בסדר עולה). הנה הגליון המקורי ולצדו הגליון הממוין –
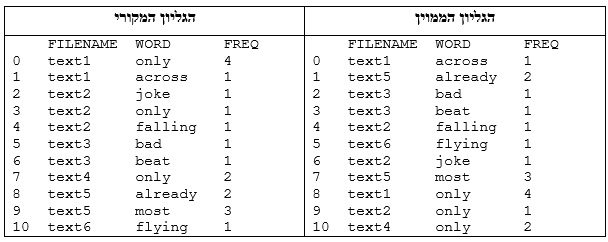
ההוראה היחידה בפונקציה היא ארוכה למדי ויש מי שיחשיבוה בתור קשה מספיק להבנה כדי להימנע כאן משימוש בביטוי Comprehension.
(ג) הפתרון שנציע לשאלה בסעיף זה יתבסס על הפונקציה tableByInds, וגם על האבחנה שהצגנו בסוף הפתרון לסעיף א’: האינדקסים ברשימה המועברת לפונקציה tableByInds אינם חייבים להופיע לפי סדרם בגליון הנתונים, כלומר בסדר עולה. מאבחנה זו עולה מסקנה חשובה הנוגעת לפתרון לסעיף הנוכחי: הפונקציה tableByInds תוכל לתת לנו מילון המייצג את הגליון הממוין, אם נעיין בערכים שיש במשתנה colName בגליון הממוין, לפי הסדר, ונעביר ל-tableByInds רשימה של האינדקסים שבהם ממוקמים הערכים האלה במשתנה colname בגליון המקורי. כדי להבין למה הכוונה עיינו במצב עניינים זה: נניח למשל שאנו רוצים למיין את הגליון לפי WORD בסדר עולה. מניסוח השאלה יוצא כי נוכל לעשות זאת באמצעות זימון זה –
תנו דעתכם –
(1) המילה בתצפית הראשונה בגליון הממוין, ‘across’, מופיעה בתצפית השניה, כלומר התצפית שהאינדקס שלה הוא 1, בגליון המקורי;
(2) המילה בתצפית השניה בגליון הממוין, ‘already’, מופיעה בתצפית התשיעית, כלומר התצפית שהאינדקס שלה הוא 8, בגליון המקורי;
(3) המילה בתצפית השלישית בגליון הממוין, ‘bad’, מופיעה בתצפית הששית, כלומר התצפית באינדקס 5 בעמודה WORD בגליון המקורי;
וכן הלאה. אם נאסוף את כל האינדקסים מהגליון המקורי לפי סדר הערכים במשתנה WORD בגליון הממוין, מהראשון לאחרון, נקבל את הרשימה הזאת –
[1, 8, 5, 6, 4, 10, 2, 9, 0, 3, 7]
ואם עתה נעביר את הרשימה הזאת לפונקציה tableByInds, היא תחזיר מילון המייצג את גליון הנתונים הממוין.
מאליה עולה השאלה: כיצד לקבל את רשימת האינדקסים שתועבר לפונקציה tableByInds לפני שיש בידינו את גליון הנתונים הממוין? התשובה היא שאנו יכולים לדעת בוודאות מה יהיה סדר הערכים במשתנה המיון – למשל WORD – בגליון הממוין: כל שעלינו לעשות הוא למיין בנפרד את הערכים הנמצאים ברשימה שאליה ממופה משתנה זה במילון המייצג את הגליון המקורי. והעיקר: הערכים ברשימה זו לא ימוינו לבדם אלא יחד עם האינדקסים שהם מופיעים בהם בגליון המקורי. עיינו בקוד הזה –
valuesAndIndices = []
for ind in range(len(table[colname])):
valuesAndIndices.append([table[colname][ind], ind])
הקטע סורק את האינדקסים ברשימה שאליה משויך המפתח colname במילון המקורי table – לדוגמה האינדקסים של הערכים בעמודה WORD. כל האינדקסים האלה מוכנסים לפי סדר הסריקה, יחד עם הערכים, לרשימה של רשימות; בכל רשימה פנימית מופיע הערך ואחר כך האינדקס. הנה דוגמה לרשימה הנוצרת בסריקת האינדקסים של הרשימה שאליה ממופה ‘WORD’ –
[[‘only’, 0], [‘across’, 1], [‘joke’, 2], [‘only’, 3],
[‘falling’, 4], [‘bad’, 5], [‘beat’, 6], [‘only’, 7],
[‘already’, 8], [‘most’, 9], [‘flying’, 10]]
אם נמיין רשימה זו, למשל כך –
valuesAndIndices = sorted(valuesAndIndices, reverse = rev)
נקבל רשימה שבה הערכים ברשימה שאליה ממופה ‘WORD’ – וכללית: הערכים ברשימה שאליה ממופה colName – מופיעים בסדר שבו יופיעו בגליון הנתונים שמוין לפי colName (המיון כאן הוא בסדר עולה או יורד, לפי הערך שהועבר לפרמטר rev). הנה הרשימה valuesAndIndices לאחר שמוינה –
[[‘across’, 1], [‘already’, 8], [‘bad’, 5], [‘beat’, 6], [‘falling’, 4], [‘flying’, 10], [‘joke’, 2], [‘most’, 9], [‘only’, 0], [‘only’, 3], [‘only’, 7]]
שימו לב להתאמה בין סדר המילים ברשימה זו לבין סדר המילים בגליון הנתונים הממוין שהוצג למעלה: ‘across’ היא המילה בתצפית הראשונה במשתנה WORD בגליון הממוין; ‘already’ היא המילה בתצפית השניה בגליון הממוין, וכן הלאה. כמו כן שימו לב שהאינדקסים ברשימה ממוינת זו מאורגנים בדיוק לפי הסדר שעליהם להופיע ברשימה שיש להעביר לפונקציה tableByInds כדי ליצור את הגליון הממוין. מכאן שעתה עלינו לסרוק את הרשימה הממוינת ולאסוף את כל האינדקסים המופיעים בה לרשימת אינדקסים אחת, למשל כך –
inds = []
for item in valuesAndIndices:
inds.append(item[1])
כל שנותר הוא להעביר את רשימת האינדקסים inds לפונקציה tableByInds. הנה הפונקציה sortTable במלואה –
def sortTable(table, colname, rev = False):
valuesAndIndices = []
for ind in range(len(table[colname])):
valuesAndIndices.append([table[colname][ind], ind])
valuesAndIndices = sorted(valuesAndIndices, reverse = rev)
indsList = []
for item in valuesAndIndices:
indsList.append(item[1])
return tableByInds(table, indsList)
print(sortTable(freqDict, ‘WORD’, True))
>>>
{‘FILENAME’: [‘text4’, ‘text2’, ‘text1’, ‘text5’, ‘text2’, ‘text6’,
‘text2’, ‘text3’, ‘text3’, ‘text5’, ‘text1’],
‘WORD’: [‘only’, ‘only’, ‘only’, ‘most’, ‘joke’, ‘flying’, ‘falling’,
‘beat’, ‘bad’, ‘already’, ‘across’],
‘FREQ’: [‘2’, ‘1’, ‘4’, ‘3’, ‘1’, ‘1’, ‘1’, ‘1’, ‘1’, ‘2’, ‘1’]}
כאן העברנו ארגומנט True לפרמטר rev של הפונקציה sortable ולכן המיון הוא בסדר יורד. המילון מייצג את הגליון הזה –
FILENAME WORD FREQ
0 text4 only 2
1 text2 only 1
2 text1 only 4
3 text5 most 3
4 text2 joke 1
5 text6 flying 1
6 text2 falling 1
7 text3 beat 1
8 text3 bad 1
9 text5 already 2
10 text1 across 1
אפשר לקצר את הפתרון, למשל כך –
def sortTable(table, colname, rev = False):
valuesAndIndices=[[table[colname][ind], ind] for ind in range(len(table[colname]))]
valuesAndIndices = sorted(valuesAndIndices, reverse = rev)
return tableByInds([item[1] for item in valuesAndIndices], indsList)
כאן השתמשנו בשני ביטויי List Comprehension כדי לקצר את שתי הלולאות הבונות אוסף חדש תוך סריקת אוסף נתון. הביטוי השני (בשורה השלישית) יוצר את רשימת האינדקסים המועברת לפונקציה tableByInds.