פרק שמיני
רשומה וקבוצה

תוכן העניינים
הוראות המופיעות בגוף של מבנה while ומתבצעות כל עוד תנאי הלולאה מתקיים צריכות להיות מוזזות ימינה ביחס לשורה הראשונה במבנה. הקוד התקין:
age = input(‘Insert age; -1 to stop: ‘)
while age != ‘-1’:
print(age)
age = input(‘Insert age; -1 to stop: ‘)
(1) מבוא
הן מחרוזת הן רשימה הם אוספים סדורים, כלומר אוספים שמוגדר סדר בערכיהם ושאפשר לגשת לערכים בהם באמצעות מערכת אינדקסים. כפי שראינו, לרשימות ולמחרוזות יש עוד מן המשותף, בייחוד בכל הנוגע לפעולות שאפשר לבצע עליהן, כגון יצירת עותקים של מקטעים, סריקה בלולאת for, ועוד. לאור זאת היינו יכולים לשאול: מדוע יש צורך בשני סוגי האוספים האלה ובייחוד במחרוזת? מדוע לא להסתפק ברשימות? התשובה לשאלה זו כבר ניתנה לעיל: שמירת נתונים בתור מחרוזת מאפשרת פעולות של עיבוד נתונים שאי אפשר לבצען או שקשה לבצען אם נשמור את הנתונים בתור רשימה. באמצעות קריאת תכנו של קובץ למחרוזת נוכל להפעיל בקלות על תוכן זה פעולות במחרוזות, כגון קביעת ה-case, “החלפת” תווים, וכו’. גם ההפך נכון: שמירת נתונים בתור רשימה מאפשרת פעולות של עיבוד נתונים שאי אפשר לבצען או שקשה לבצען אם נשמור את הנתונים בתור מחרוזת. כך למשל באמצעות המרת מחרוזת שהיא תוכן של קובץ טקסט, לרשימה, נוכל לגשת בקלות לכל המילים בקובץ. הכלל היוצא מאבחנות אלו הוא שנשאף לשמור נתונים בסוג של אוסף ערכים המאפשר את עיבודם או מקל עליו. חוץ ממחרוזת ורשימה פייתון מעמידה לרשותנו מגוון של סוגי אוספים. בפרק זה נתוודע לשניים מהם: קבוצה ורשומה. נתמקד בהיבטים המעשיים של השימוש בהם, וגם הפעם נציג את ההוראות הנלמדות בהקשר של ניתוח נתונים ספציפיים.
(2) תכנית המכוניות
בבסיס הדיון בפרק הנוכחי עומד סיפור דמיוני מסוים, והוא זה: בשנת 2019 נמכרו בישראל עשרות אלפי מכוניות, וכך גם בשנת 2020. בתום כל אחת מהשנים האלה הוכן קובץ טקסט המפרט את צבעיה של כל אחת ואחת מהמכוניות שנמכרו בשנה החולפת. כל אחד מהקבצים מכיל מספר שורות כמספר המכוניות שנמכרו, ובכל שורה יש מספר רישוי של מכונית, ומילה אחת – שם של צבע המכונית הזאת. במה שלהלן נכתוב תכנית הפותרת בעיה זו:
יש ליצור רשימה בלי כפילויות של כל מספרי הרישוי של מכוניות
שנמכרו בשנת 2020 והיו להן צבעים שלא היו למכוניות שנמכרו בשנת 2019.
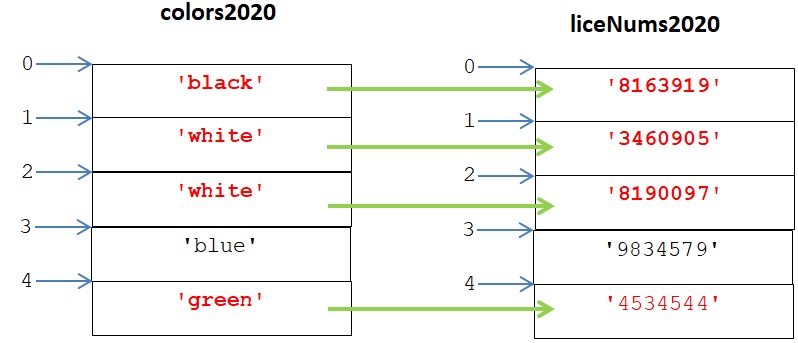
לצורך הפשטות נשתמש בגרסות מוקטנות של שני קבצי הנתונים. שמות הקבצים המוקטנים: colors2019.txt ו-colors2020.txt (הקישו על השמות כדי להוריד את הקבצים). כל אחד מהם מכיל 5 שורות בלבד, כדלקמן:
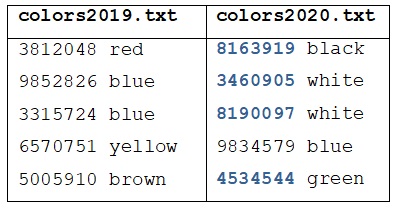
בהתבסס על שני קבצים אלה, המטרה הסופית של התכנית תהיה ליצור את רשימת מספרי הרישוי הזאת:
[‘8163919’, ‘3460905’, ‘8190097’, ‘4534544’]
לפי הקובץ colors2020.txt מספרי רישוי אלה היו למכוניות שנמכרו בשנת 2020, וצבעיהן של המכוניות הללו היו שחור, לבן וירוק. לפי הקובץ colors2019.txt שלושת הצבעים האלו לא היו למכוניות שנמכרו בשנת 2019.
בכתיבת התכנית נתקדם בחמישה שלבים עיקריים אלה:
(1) נשמור את המידע בנוגע למכוניות בשני אוספים נפרדים – אוסף אחד ישמור את המידע בקובץ colors2019.txt ואוסף אחר ישמור את המידע בקובץ colors2020.txt.
(2) ניצור שני אוספים של צבעים: אוסף צבעים א’ לכל הצבעים שהיו למכוניות שנמכרו בשנת 2019, ואוסף צבעים ב’ לכל הצבעים שהיו למכוניות שנמכרו בשנת 2020.
(3) נסיר כפילויות מאוסף צבעים א’ ומאוסף צבעים ב’.
(4) ניצור אוסף חדש, אוסף צבעים ג’, המכיל את כל הצבעים באוסף צבעים ב’, שאינם מופיעים באוסף צבעים א’ – אלו הם הצבעים שהיו למכוניות שנמכרו בשנת 2020 ולא היו למכוניות שנמכרו בשנת 2019.
(5) ניצור אוסף חדש המכיל את כל מספרי הרישוי של מכוניות שנמכרו בשנת 2020 ויש להן הצבעים המופיעים באוסף צבעים ג’.
נפתח בדיון בצעד 1, כלומר קריאת המידע האצור בשני הקבצים, ודיון זה יוביל אותנו להיכרות עם אחד משני סוגי האוספים שהם במוקד ענייננו בפרק זה: רשומה.
(3) מדוע לשמור נתונים ברשומה?
נפתח בקריאת המידע מהקבצים colors2019.txt ו-colors2020.txt ושמירתו. הנה קוד מתאים לשמירת המידע בקובץ colors2019.txt ברשימה:
f = open(‘colors2019.txt’, ‘r’)
s = f.read()
f.close()
lines = s.split(‘\n’)
liceNumsAndColors2019 = [ ]
for line in lines:
liceNumsAndColors2019.append(line.split())
print(liceNumsAndColors2019)
>>>
[[‘3812048’, ‘red’], [‘9852826’, ‘blue’], [‘3315724’, ‘blue’], [‘6570751’, ‘yellow’], [‘5005910’, ‘brown’]]
הקוד פותח בקריאת כל תכנו של הקובץ colors2019.txt ושמירתו במשתנה-מחרוזת s. אחר כך הפונקציה split מפרקת את המחרוזת הזאת למחרוזות-שורות, יוצרת ממחרוזות אלו רשימה, ומציבה את הרשימה במשתנה lines. הנה הרשימה lines:
[‘3812048 red’,
‘9852826 blue’,
‘3315724 blue’,
‘6570751 yellow’,
‘5005910 brown’]
בשלב הבא לולאת ה-for סורקת מחרוזת-מחרוזת ברשימה זו, וכל אחת ממחרוזות אלו מפורקת – שוב באמצעות הפונקציה split – לזוג: מחרוזת המייצגת מספר רישוי, ומחרוזת שהיא שם של צבע. כל זוג נשמר ברשימה, וכל הרשימות האלה מוכנסות בתוך רשימות פנימיות לרשימה אחת ששמה liceNumsAndColors2019.
באופן דומה נשמור את המידע המופיע בקובץ colors2020.txt. הנה הקוד העושה זאת.
f = open(‘colors2020.txt’, ‘r’)
s = f.read()
f.close()
lines = s.split(‘\n’)
liceNumsAndColors2020 = [ ]
for line in lines:
liceNumsAndColors2020.append(line.split())
print(liceNumsAndColors2020)
>>>
[[‘8163919’, ‘black’], [‘3460905’, ‘white’], [‘8190097’, ‘white’], [‘9834579’, ‘blue’], [‘4534544’, ‘green’]]
ניתן דעתנו שכל אחת משתי הרשימות שיצרנו, liceNumsAndColors2019 ו-liceNumsAndColors2020, מבוססת על קובץ שהוכן לאחר שתמה שנת מכירות (2019 ו-2020), ואותרו כל המכוניות שנמכרו בשנה זו בישראל. המידע המופיע בקבצים וגם ברשימות liceNumsAndColors2019 ו-liceNumsAndColors2020 הוא אפוא סופי: אין כוונה להוסיף עליו, להחסיר ממנו, או לשנותו.
בנוסף, לכל הרשימות הפנימיות בתוך שתי הרשימות שיצרנו יש מבנה מסוים. כל רשימה פנימית כזו היא מסודרת ומוגדרים אינדקסים לערכים בה (0 ו-1). ואולם לא רק האינדקסים מבחינים בין כל אחד משני הערכים בה, אלא גם המשמעויות המוגדרות המוקצות להם: הערך הראשון הוא מספר רישוי, ואילו הערך השני הוא שם צבע. על כל רשימה פנימית כזאת אפשר להסתכל בתור אוסף של (שתי) תכונות שונות זו מזו של עצם אחד: מכונית. ולמעשה אפשר להסתכל על הנתונים בכל אחד משני קבצי הטקסט בתור שתי עמודות מתוך גליון נתונים או בסיס נתונים בנוגע למכוניות שנמכרו בישראל. כך יכול להראות בסיס הנתונים:
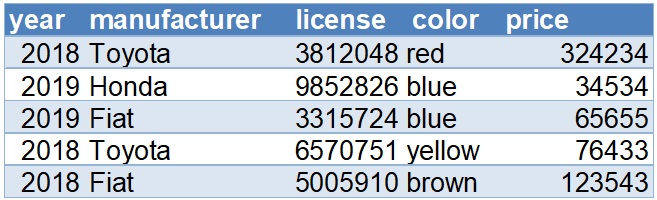
במצב עניינים זה, דהיינו כשיש בידינו אוסף ערכים שאין כוונה לשנותו, ובייחוד כאשר נרצה לשמור נתונים (או: תכונות) של אוסף עצמים במבנה של בסיס נתונים, נעדיף לשמור את האוסף לא ברשימה כי אם בסוג אחר של אוסף ערכים בפייתון: רשומה (tuple). כמו רשימה גם רשומה היא אוסף של אפס או יותר ערכים שיכולים להיות מסוגים מגוונים. בה בעת שלא כמו רשימה, אי אפשר לשנות את הרכבה של רשומה, כלומר להוסיף לה ערכים ולמחוק ממנה ערכים (אמנם כפי שנראה להלן אפשר לשנות ערכים מסוגים מסוימים הכלולים בה). אי היכולת לשנות הרכב של רשומה הופך קוד הנסמך על שמירת נתונים בה ליעיל יותר מבחינת ניהול הזמן והזכרון מקוד הנסמך על שמירת נתונים ברשימה, וככלל מקוד הנסמך על שמירת נתונים באוסף שאפשר לשנותו במקום. לאור זאת בתכנית צבעי המכוניות נעדיף לשמור את הצבעים בתוך רשומות ולא בתוך רשימות. קצת הלאה בפרק זה נראה את הקוד העושה זאת. קודם נאמר מילים אחדות נוספות על אודות רשומה.
(4) רשומה – סוג של רצף
רשומה היא סוג של אוסף ערכים. שמו: tuple.
סממן ההיכר הצורני של רשומה הוא סוגריים עגולים התוחמים את הערכים המוכלים בה. דוגמה:
tup = (5, ‘hello’, True)
כאמור כמו ערכים ברשימה גם ערכים ברשומה יכולים מסוגים מגוונים. וכמו מחרוזת ורשימה, גם רשומה היא רצף (sequence), כלומר היא אוסף של ערכים שמוגדר בו סדר ומערכות אינדקסים. בתור רצף, אפשר לבצע ברשומה את מגוון הפעולות ברצפים שהכרנו בפרק הרביעי ובפרק החמישי. הנה מקצת פעולות אלו ודוגמות לביצוען ברשומות.
חישוב מספר ערכים (אורך) – הפונקציה len
tup = (5, ‘hello’, True)
tupLen = len(tup)
print(tupLen)
>>>
3
צירוף והכפלה – האופרטורים + ו-*
tup = (5, ‘hello’, True) + (8.3, [‘one’, ‘two’])
print(tup)
>>>
(5, ‘hello’, True, 8.3, [‘one’, ‘two’])
tup = (5, ‘hello’, True) * 2
print(tup)
>>>
(5, ‘hello’, True, 5, ‘hello’, True)
בדיקת הכלה ואי הכלה – האופרטורים in ו-not in
tup = (5, ‘hello’, True)
resultIn = 5 in tup
resultNotIn = 5 not in tup
print(resultIn)
print(resultNotIn)
>>>
True
False
יצירת עותק של ערך ברצף ויצירת עותק של מקטע רצף – האופרטור [ ]
tup = (5, ‘hello’, True)
newTup1 = tup[2]
newTup2 = tup[0:2]
print(newTup1)
print(newTup2)
>>>
True
(5, ‘hello’)
סריקת רצף בלולאת for
tup = (5, ‘hello’, True)
for item in tup:
print(item)
>>>
5
hello
True
כאמור אלו רק אחדות מהפעולות המוגדרות ברשומות בתור רצפים.
(5) יצירת רשומה
אפשר ליצור רשומה במפורש באמצעות כתיבת אוסף ערכים המופרדים זה מזה בפסיקים ותחימתו בסוגריים עגולים. דוגמה:
tup = (‘another’, ‘brick’, ‘in’, ‘the’, ‘wall’)
תנו דעתכם: כדי לציין רשומה שיש בה ערך אחד בדיוק עלינו לכתוב פסיק לאחר הערך. דוגמה:
tup = (5,)
אם לא נציין את הפסיק ונכתוב כך:
tup = (5)
יוצב במשתנה tup ערך מסוג מספר שלם (המספר 5):
tup = (5)
print(type(tup))
>>>
<class ‘int’>
אפשר להגדיר במפורש אוסף ערכים בתור רשומה גם ללא ציון הסוגריים העגולים, דוגמות:
tup = ‘another’, ‘brick’, ‘in’, ‘the’, ‘wall’
print(type(tup))
>>>
<class ‘tuple’>
tup = 5,
print(type(tup))
>>>
<class ‘tuple’>
גם כאן, ביצירת רשומה שיש בה ערך אחד, לא שכחנו לציין פסיק לאחר הערך.
כדי לציין רשומה ריקה לא נכתוב דבר בתוך הסוגריים העגולים. דוגמה:
tup = ()
אפשר גם ליצור רשומה ריקה באמצעות הפונקציה tuple. נזמן אותה בלי להעביר אליה ארגומנטים:
tup = tuple()
אם ניתן לפונקציה tuple רשימה היא תמיר אותה לרשומה. דוגמה:
lst = [‘we’, ‘used’, ‘to’, ‘constitute’, ‘a’, ‘list’]
tup = tuple(lst)
print(tup)
>>>
(‘we’, ‘used’, ‘to’, ‘constitute’, ‘a’, ‘list’)
כאמור נרצה לשמור את המידע בקבצים colors2019.txt ו-colors2020.txt ברשומות. נעשה זאת באופן דומה לשמירת הנתונים בקבצים אלה ברשימות liceNumsAndColors2019 ו-liceNumsAndColors2020 (ראו לעיל, סעיף 3). הפעם liceNumsAndColors2019 ו-liceNumsAndColors2020 יהיו שמות לשתי רשומות. בנוסף המידע על כל מכונית ומכונית – מספר הרישוי שלה ושם צבעה – יהיו שמור ברשומות פנימיות. זו תהיה הרשומה liceNumsAndColors2019:
((‘3812048’, ‘red’), (‘9852826’, ‘blue’), (‘3315724’, ‘blue’), (‘6570751’, ‘yellow’), (‘5005910’, ‘brown’))
וזו תהיה הרשומה liceNumsAndColors2020:
((‘8163919’, ‘black’), (‘3460905’, ‘white’), (‘8190097’, ‘white’), (‘9834579’, ‘blue’), (‘4534544’, ‘green’))
נתחיל ביצירת הרשומה liceNumsAndColors2019, ונראה שתי דרכים ליצור אותה. בדרך הראשונה ניצור רשימה של רשומות, ולאחר מכן נשתמש בפונקציה tuple כדי להמיר את הרשימה לרשומה. הנה הקוד היוצר את הרשימה לפני ההמרה לרשומה:
f = open(‘colors2019.txt’, ‘r’)
s = f.read()
f.close()
lines = s.split(‘\n’)
liceNumsAndColors2019 = []
for line in lines:
liceNumsAndColors2019.append(tuple(line.split()))
print(liceNumsAndColors2019)
>>>
[(‘3812048’, ‘red’), (‘9852826’, ‘blue’), (‘3315724’, ‘blue’), (‘6570751’, ‘yellow’), (‘5005910’, ‘brown’)]
כאן בכל סיבוב וסיבוב המרנו את ערך ההחזרה של הפונקציה split: מרשימה של שתי מחרוזות – האחת למספר הרישוי והשנייה לצבע – לרשומה, ועשינו זאת באמצעות הפונקציה tuple. באמצעות הפונקציה append הוספנו את הרשומה הזאת לסופה של הרשימה liceNumsAndColors2019. לקוד הזה נוסיף הוראה אחת נוספת המזמנת את הפונקציה tuple כדי להמיר את הרשימה liceNumsAndColors2019 לרשומה. הנה הקוד המעודכן:
f = open(‘colors2019.txt’, ‘r’)
s = f.read()
f.close()
lines = s.split(‘\n’)
liceNumsAndColors2019 = []
for line in lines:
liceNumsAndColors2019.append(tuple(line.split()))
liceNumsAndColors2019 = tuple(liceNumsAndColors2019)
print(liceNumsAndColors2019)
>>>
((‘3812048’, ‘red’), (‘9852826’, ‘blue’), (‘3315724’, ‘blue’), (‘6570751’, ‘yellow’), (‘5005910’, ‘brown’))
דרך שונה מזו ליצירת רשומת הרשומות liceNumsAndColors2019 היא להגדיר אותה לכתחילה בתור רשומה ריקה, ולהוסיף לתוכה את הרשומות הפנימיות. לא נוכל לבצע את ההוספה באמצעות הפונקציה append או פונקציה דומה לה, כיוון שאי אפשר לשנות רשומה במקום, ובייחוד אי אפשר להוסיף ערך לסוף רשומה נתונה. אמנם נוכל להשתמש באופרטור + וליצור רשומה חדשה המורכבת מרשומה קיימת בתוספת ערך חדש. כאן יהיה עלינו לשים לב לאופן הכתיבה בהוספת רשומה פנימית לרשומה של רשומות. עיינו בקוד הזה:
tup = ((‘8163919’, ‘black’), (‘3460905’, ‘white’))
newTup = tup + (‘8190097’, ‘white’)
print(newTup)
>>>
((‘8163919’, ‘black’), (‘3460905’, ‘white’), ‘8190097’, ‘white’)
tup היא רשומה של רשומות. שלא כפי שאפשר לחשוב, ההוראה השנייה אינה מוסיפה לרשומה tup רשומה פנימית. במקום זה היא מוסיפה לרשומה tup את הערכים שיש ברשומה האחרת. אם ברצוננו להוסיף את הרשומה האחרת בתור רשומה פנימית לסוף הרשומה tup, עלינו להגדיר את הרשומה האחרת בתור רשומה פנימית יחידה ברשומה חיצונית, ולכתוב כך:
tup = ((‘8163919’, ‘black’), (‘3460905’, ‘white’))
newTup = tup + ((‘8190097’, ‘white’),)
print(newTup)
>>>
((‘8163919’, ‘black’), (‘3460905’, ‘white’), (‘8190097’, ‘white’))
תחמנו את הרשומה האחרת בסוגריים עגולים והנחנו פסיק לפני הסוגר העגול הסוגר. כך היא הוגדרה בתור רשומה פנימית יחידה ברשומה חיצונית. עתה כשנפעיל את האופרטור + נקבל את התוצאה המבוקשת.
לאור האמור נכתוב כך את הקוד השומר ברשומה את המידע בקובץ colors2019.txt:
f = open(‘colors2019.txt’, ‘r’)
s = f.read()
f.close()
lines = s.split(‘\n’)
liceNumsAndColors2019 = ()
for line in lines:
liceNumsAndColors2019 = liceNumsAndColors2019 + (tuple(line.split()),)
print(liceNumsAndColors2019)
>>>
((‘3812048’, ‘red’), (‘9852826’, ‘blue’), (‘3315724’, ‘blue’), (‘6570751’, ‘yellow’), (‘5005910’, ‘brown’))
שני ההבדלים העיקריים בין הקוד הזה לבין הקוד ששמר הנתונים ברשימה של רשומות פנימיות מסומנים בגופן עבה.
השינוי הראשון הוא יצירת רשומה ריקה במקום רשימה ריקה. שם הרשומה הריקה liceNumsAndColors2019.
השינוי השני נוגע לפעולת ההוספה בגוף לולאת ה-for. בכל סיבוב הוראה זו צריכה להוסיף לרשומה liceNumsAndColors2019 רשומה של הזוג (מספר רישוי ומספר צבע) הנוכחי. כדי ליצור את הרשומה הזאת השתמשנו בפונקציה tuple: באמצעותה המרנו את הרשימה שהחזירה הפונקציה split לרשומה. את הרשומה הזאת הגדרנו בתור ערך יחיד ברשומה (באמצעות הקפתה בסוגרים עגולים והוספת פסיק לפני הסוגר העגול הסוגר) כדי שבהפעלת האופרטור + הרשומה תוכנס בתור רשומה עצמאית לרשומה liceNumsAndColors2019 (ולא יוכנסו זוג הערכים בה, כל אחד בנפרד, לסוף הרשומה הזאת). למשל בסיבוב הראשון מתבצעת הפעולה הזאת למעשה:
() + (tuple([‘3812048’, ‘red’]),)
ומתקבלת הרשומה הזאת:
((‘3812048’, ‘red’),)
לו היינו כותבים כך:
() + tuple([‘3812048’, ‘red’])
כל מחרוזת ברשומה שהפונקציה tuple מחזירה הייתה מוספת בנפרד לסוף הרשומה הנוצרת, והייתה מתקבלת הרשומה הזאת:
(‘3812048’, ‘red’)
נכתוב קוד דומה כדי לשמור ברשומה את המידע בקובץ colors2020.txt:
f = open(‘colors2020.txt’, ‘r’)
s = f.read()
f.close()
lines = s.split(‘\n’)
liceNumsAndcolors2020 = ()
for line in lines:
liceNumsAndcolors2020 = liceNumsAndcolors2020 + (tuple(line.split()),)
print(liceNumsAndcolors2020)
>>>
((‘8163919’, ‘black’), (‘3460905’, ‘white’), (‘8190097’, ‘white’), (‘9834579’, ‘blue’), (‘4534544’, ‘green’))
נסיונות לשנות את הרשומות שיצרנו יוליכו להודעת שגיאה. כך יקרה למשל בקוד זה:
liceNumsAndColors2020[0][1] = ‘yellow’
>>>
liceNumsAndColors2020[0][1] = ‘yellow’
TypeError: ‘tuple’ object does not support item assignment
הקוד ניגש לרשומה הפנימית הראשונה ברשומה liceNumsAndColors2020. זה תכנה:
(‘8163919’, ‘black’)
הקוד מנסה לשנות את מחרוזת הצבע ברשומה זו מ-‘black’ ל-‘yellow’. התוצאה: שגיאה.
(6) שינוים עקיפים ברשומה
נעיר כי אף שאי אפשר לשנות את ההרכב של רשומה. בכל זאת אפשר לשנות הרכב של אוספים המוכלים ברשומה, אם אפשר לשנות אוספים אלה במקום. בשעה זו מוכר לנו רק סוג אחד של אוסף שאפשר לשנותו במקום – רשימה. ואמנם אפשר לשנות רשימה המוכלת ברשומה.
נניח למשל שחוץ מרשומות פנימיות של מספרי רישוי וצבעים יש ברשומה liceNumsAndColors2020 ערך נוסף: רשימה המתעדת את מספר השנים שחלפו מאז שנוצר הקובץ colors2020.txt, ומחרוזת המציינת את המקום שבו שמור תדפיס של הקובץ. רשימה זו מופיעה בראש הרשומה liceNumsAndColors2020:
([2, ‘Office52’], (‘8163919’, ‘black’), (‘3460905’, ‘white’), (‘8190097’, ‘white’), (‘9834579’, ‘blue’), (‘4534544’, ‘green’))
אם נרצה נוכל לעדכן את הערכים ברשימה הפנימית הזאת. לדוגמה נוכל לשנות את מספר השנים המופיע ברשימה:
liceNumsAndColors2020[0][0] = liceNumsAndColors2020[0][0] + 1
כאן הגדלנו ב-1 את המספר 2 השמור בתור ערך ראשון ברשימה הפנימית. השינוי ישתקף ברשומה liceNumsAndColors2020 עצמה (דהיינו, השינוי ייעשה במקום):
([3, ‘Office52’], (‘8163919’, ‘black’), (‘3460905’, ‘white’), (‘8190097’, ‘white’), (‘9834579’, ‘blue’), (‘4534544’, ‘green’))
(7) פירוק רצף
הנה שתי הרשומות שיש בידינו בשלב זה – זו הרשומה liceNumsAndColors2019:
((‘3812048’, ‘red’), (‘9852826’, ‘blue’), (‘3315724’, ‘blue’), (‘6570751’, ‘yellow’), (‘5005910’, ‘brown’))
וזו הרשומה liceNumsAndColors2020:
((‘8163919’, ‘black’), (‘3460905’, ‘white’), (‘8190097’, ‘white’), (‘9834579’, ‘blue’), (‘4534544’, ‘green’))
הפעולות שנרצה לבצע בשתי הרשומות בהמשך התכנית יחייבו אותנו להחזיק את שמות הצבעים באוספים נפרדים ממספרי הרישוי. כלומר עלינו להכין אוספים אלה:
• אוסף מספר הרישוי של מכוניות שנמכרו בשנת 2019
‘3812048’, ‘9852826’, ‘3315724’, ‘6570751’, ‘5005910’
• אוסף שמות הצבעים של מכוניות שנמכרו בשנת 2019
‘red’, ‘blue’, ‘blue’, ‘yellow’, ‘brown’
• אוסף מספר הרישוי של מכוניות שנמכרו בשנת 2020
‘8163919’, ‘3460905’, ‘8190097’, ‘9834579’, ‘4534544’
• ואוסף שמות הצבעים של מכוניות שנמכרו בשנת 2020
‘black’, ‘white’, ‘white’, ‘blue’, ‘green’
כדי לפרק את שתי הרשומות לארבעת אוספים אלה נשתמש בהוראות הכתובות בתחביר שטרם ראינו. נתחיל ונתבונן ברשומה הפנימית הראשונה שיש עכשיו ברשומה liceNumsAndColors2019. נניח שהיא מוצבת במשתנה בשם firstTup.
firstTup = liceNumsAndColors2019[0]
print(firstTup)
>>>
(‘3812048’, ‘red’)
אם נרצה לפרק רשומה זו לשני ערכים נפרדים – מספר רישוי וצבע – נוכל לעשות זאת באמצעות האופרטור [ ] כך:
liceNum = firstTup[0]
color = firstTup[1]
print(liceNum)
print(color)
>>>
‘3812048’
‘red’
בה בעת נוכל לכתוב את הפירוק בדרך מקוצרת באמצעות כתיבה בתחביר של פירוק רצף (sequence unpacking). פירוק רצף היא פירוק אוסף ערכים סדור לערכים המרכיבים אותו. פעולה זו מתבצעת בכמה הקשרים בפייתון. כאן נתמקד באחד ההקשרים – השמה מרובה (multiple assignment): יש בידינו אוסף ערכים ואנו רוצים להציב כל ערך בו במשתנה נפרד; מספר המשתנים שווה למספר הערכים. הנה דוגמה:
liceNum, color = (‘3812048’, ‘red’)
print(liceNum)
print(color)
>>>
‘3812048’
‘red’
הביצוע בהוראת הפירוק, ההוראה הראשונה בקוד, הוא מימין לשמאל: כל ערך ברשומה המופיעה בצד הימני של הוראת ההשמה, מושם לפי הסדר במשתנה המופיע בצדה השמאלי של ההוראה: כלומר המחרוזת ‘3812048’ במשתנה liceNum והמחרוזת ‘red’ במשתנה colors.
נדגיש שוב: מן ההכרח שמספר הערכים באוסף המפורק יהיה שווה למספר המשתנים שהערכים האלה מוצבים בהם. אי שיוויון יוליך לשגיאה. לדוגמה הרצת הוראה זו:
liceNum, color = (‘3812048’, ‘red’, ‘blue’)
תוציא הודעת שגיאה כדלקמן:
liceNum, color = (‘3812048’, ‘red’, ‘blue’)
ValueError: too many values to unpack (expected 2)
אפשר להשתמש בתחביר של פירוק רצף גם בפירוק של רשימה ומחרוזת. דוגמות:
lst = [‘blue’, ‘red’, ‘green’]
name1, name2, name3 = lst
print(name1)
print(name2)
print(name3)
>>>
blue
red
green
initials = ‘b.r.g.’
ch1, ch2, ch3, ch4, ch5, ch6 = initials
print(ch1)
print(ch2)
print(ch3)
print(ch4)
print(ch5)
print(ch6)
>>>
b
.
r
.
g
.
אפשר לבצע הוראת השמה מרובה גם בלולאת for. למשל עיינו בקוד הזה:
for tup in liceNumsAndColors2019:
print(tup[0], tup[1])
>>>
‘3812048’ ‘red;
‘9852826’ ‘blue;
‘3315724’ ‘blue’
‘6570751’ ‘yellow’
‘5005910’ ‘brown’
הלולאה כאן סרקה רשומה פנימית אחר רשומה פנימית ברשומה liceNumsAndColors2019. בכל סיבוב הוצבה הרשומה הפנימית הנוכחית במשתנה הלולאה tup. הוראת ההדפסה בגוף הלולאה השתמשה באופרטור [ ] כדי לגשת לשני הערכים בתוך כל רשומה.
עתה עיינו בקוד הזה:
for liceNum, color in liceNumsAndColors2019:
print(liceNum, color)
>>>
‘3812048’ ‘red’
‘9852826’ ‘blue’
‘3315724’ ‘blue’
‘6570751’ ‘yellow’
‘5005910’ ‘brown’
גם כאן הלולאה סורקת רשומה פנימית אחר רשומה פנימית ברשומה liceNumsAndColors2019. ואולם כאן בכל סיבוב מתבצעת השמה מרובה, כפי שמתואר בטבלה זו:
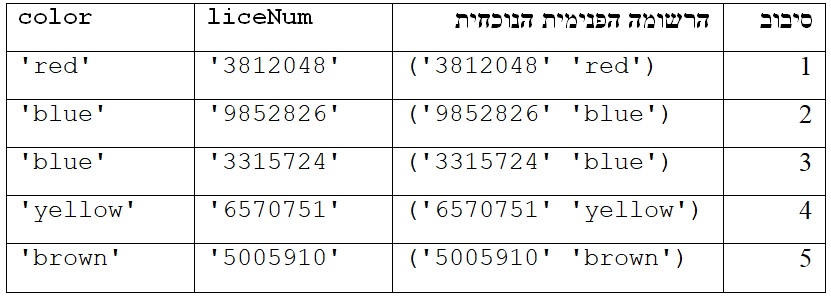
הואיל ובכניסה לגוף הלולאה שמרנו את שני הערכים ברשומה הפנימית הנוכחית והצבנו כל אחד במשתנה מובחן – liceNum ו-color – הרי בהדפסת הערכים האלה אין כבר צורך להשתמש באופרטור [ ] ובציון אינדקס, כפי שעשינו בקוד הקודם.
נשתמש בהשמה מרובה בלולאת for כדי לפרק את הרשומה liceNumsAndColors2019 לשתי רשימות אלו:
• liceNums2019 – רשימה של מספרי הרישוי
• colors2019 – רשימה של שמות צבעים
הנה הקוד:
liceNums2019 = []
colors2019 = []
for liceNum, color in liceNumsAndColors2019:
liceNums2019.append(liceNum)
colors2019.append(color)
print(liceNums2019)
print(colors2019)
>>>
[‘3812048’, ‘9852826’, ‘3315724’, ‘6570751’, ‘5005910’]
[‘red’, ‘blue’, ‘blue’, ‘yellow’, ‘brown’]
באופן דומה ניצור מהרשומה liceNumsAndColors2020 רשימת מספרי רישוי ורשימת שמות צבעים, liceNums2020 ו-colors2020:
liceNums2020 = []
colors2020 = []
for liceNum, color in liceNumsAndColors2020:
liceNums2020.append(liceNum)
colors2020.append(color)
print(liceNums2020)
print(colors2020)
>>>
[‘8163919’, ‘3460905’, ‘8190097’, ‘9834579’, ‘4534544’]
[‘black’, ‘white’, ‘white’, ‘blue’, ‘green’]
בנקודה זו השלמנו את שני השלבים הראשונים של כתיבת תכנית המכוניות. שמרנו את המידע בנוגע למכוניות בשני אוספים נפרדים – שתי רשומות – אחת למידע בקובץ colors2019.txt והאחרת למידע בקובץ colors2020.txt. אחר כך יצרנו שתי רשימות צבעים, רשימה אחת לכל הצבעים שהיו למכוניות שנמכרו בשנת 2019, ורשימה אחרת לכל הצבעים שהיו למכוניות שנמכרו בשנת 2020. בנוסף יצרנו רשימות למספרי הרישוי המופיעים בכל קובץ. כעת אנו מוכנים להתקדם לשלביה הבאים של התכנית שאנו כותבים בפרק זה, דהיינו לפעולות על רשימות הצבעים. כאן נסתייע בסוג אוסף נוסף: קבוצה.
(8) קבוצה – הגדרתה, יצירתה והוספה לה
בנקודה זו בכתיבתה של תכנית המכוניות יש בידינו רשימות אלה:
• colors2019 – רשימה השומרת את הצבעים של כל המכוניות שנמכרו בישראל בשנת 2019
• colors2020 – רשימה השומרת את הצבעים של כל המכוניות שנמכרו בישראל בשנת 2020
עתה מטרתנו היא להוציא כפילויות משתי הרשומות, ואחר כך למצוא אלו צבעים ברשימה colors2020 אינם נמצאים ברשימה colors2019. נבצע את שתי הפעולות הללו באמצעות שימוש בקבוצות. מהי קבוצה?
קבוצה היא סוג של אוסף ערכים. שמו: set.
הסממן הצורני המזהה של קבוצה הוא סוגריים מתולתלים התוחמים את הערכים שהיא מכילה. דוגמה:
newSet = {‘blue’, ‘red’, ‘green’}
תחימת אוסף שיש בו ערך אחד או יותר בסוגריים מתולתלים – זו דרך אחת ליצירת קבוצה. אפשר ליצור קבוצה גם באמצעות הפונקציה set. הפונקציה set מקבלת אוסף של ערכים – מחרוזת, רשימה או רשומה – ויוצרת ממנו קבוצה. אם היא מקבלת רשימה או רשומה היא יוצרת קבוצה מהערכים שיש בהן. דוגמות:
newSet = set([‘blue’, ‘red’, ‘green’])
print(newSet)
>>>
{‘green’, ‘blue’, ‘red’}
newSet = set((‘blue’, ‘red’, ‘green’))
print(newSet)
>>>
{‘green’, ‘blue’, ‘red’}
בדומה לפונקציה list (ראו פרק רביעי, סעיף 2) אם ניתן לפונקציה set מחרוזת, היא תפרק את המחרוזת לתווים המרכיבים אותה. דוגמה:
newSet = set(‘blue’)
print(newSet)
>>>
{‘l’, ‘u’, ‘e’, ‘b’}
שימו לב שבקבוצה המוצגת התווים אינם מסודרים לפי סדרם במחרוזת שפוצלה לתווים. מיד נסביר את הסיבה לכך.
אפשר לשער שהגדרת קבוצה ריקה, כלומר קבוצה שאין בה ערכים כלל, נעשית באמצעות כתיבת סוגריים מתולתלים שאין בהם דבר, כלומר כך:
emptySet = {}
אך אין אלה פני הדברים. כדי להגדיר קבוצה ריקה נשתמש בפונקציה set ולא ניתן לה ארגומנטים:
emptySet = set()
print(emptySet)
>>>
set()
בזימונהּ זה הפונקציה set יוצרת קבוצה ריקה ומחזירה קבוצה זו.
אפשר לראות בקבוצה סוג של רשימה. כמה מהפעולות שאפשר לעשות ברשימה אפשר לעשות גם בקבוצה. לדוגמה אפשר לבדוק אם ערך נמצא בקבוצה באמצעות האופרטור in. דוגמה:
newSet = {‘blue’, ‘red’, ‘green’}
result = ‘yellow’ in newSet
print(result)
>>>
False
אפשר גם לסרוק איברים בקבוצה באמצעות לולאת for. דוגמה:
newSet = {‘blue’, ‘red’, ‘green’}
for color in newSet:
print(color)
>>>
red
blue
green
בהמשך נראה פעולות נוספות ברשימות שאפשר לבצען גם בקבוצות. עם האמור קבוצה שונה מרשימה מבחינות אחדות. הבדל חשוב בין שני סוגי האוספים האלה הוא שקיימת מגבלה על סוגי הערכים שיכולים להיות בקבוצה: הם חייבים להיות ערכים שאי אפשר לשנותם במקום (immutable). לכן רשימה לא יכולה להיות ערך בקבוצה. נסיון להגדיר קבוצה שיש בה רשימה, יוליך לשגיאה. דוגמה:
set([‘blue’, ‘green’, [‘red’, ‘yellow’]])
>>>
set([‘blue’, ‘green’, [‘red’, ‘yellow’]])
TypeError: unhashable type: ‘list’
ההוראה כאן מנסה להגדיר קבוצה מרשימה שיש בה ערך מסוג רשימה. זה בלתי אפשרי. אותו הדין יפה בנוגע לקבוצה, הואיל ואפשר לשנות קבוצה במקום (דיון בעניין זה יובא בהמשך הסעיף הנוכחי). וגם מילון, סוג אוסף שנעיין בו בפרק הבא, אי אפשר להוסיף לקבוצה, כיוון שגם מילון אפשר לשנות במקום.
הבדל בולט אחר בין קבוצה לרשימה הוא שקבוצה אינה רצף, כלומר היא אינה אוסף סדור של ערכים. מכאן שאין מוגדרת בה מערכת אינדקסים. נתבונן בקבוצה זו:
{‘blue’, ‘red’, ‘green’}
על אף שבהגדרת הקבוצה סידרנו את שלושת הערכים בה בסדר מסוים, אין אנו יכולים להניח שהם נשמרים בזכרון המחשב בסדר זה. עיינו בקוד הזה:
newSet = {‘blue’, ‘red’, ‘green’}
print(newSet)
>>>
{‘red’, ‘blue’, ‘green’}
כפי שאפשר להיווכח, סדר הערכים בקבוצה שהודפסה שונה מסדר הערכים בהגדרת הקבוצה. מכאן שאיננו יכולים להניח את קיומו של סדר כלשהו בין ערכים בקבוצה. אם כן נשגה אם נתאר את הקבוצה newSet כך:
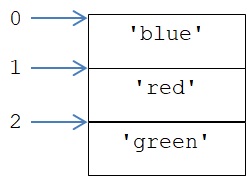
תיאור גרפי נכון של הקבוצה newSet הוא זה:
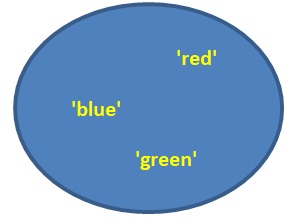
הצגה זו משקפת את אי הגדרת סדר בין איבריה של קבוצה.
הואיל ואין בקבוצה סדר ואינדקסים, אי אפשר להשתמש באופרטור [ ] כדי לשלוף ערכים מתוך קבוצה. לכן הרצת הקוד הזה תיצור שגיאה:
newSet = {‘blue’, ‘red’, ‘green’}
print(newSet[1])
>>>
print(newSet[1])
TypeError: ‘set’ object does not support indexing
ההוראה השנייה בקוד זה מנסה לגשת לערך באינדקס 1 בקבוצה newSet. כיוון שבקבוצה אין מוגדרת מערכת אינדקסים, מוצאת הודעת שגיאה.
בנוסף אי אפשר להשתמש באופרטור + כדי להוסיף קבוצה לקבוצה. דוגמה:
newSet = {‘blue’, ‘red’, ‘green’}
print(newSet + {‘yellow’})
>>>
print(newSet + {‘yellow’})
TypeError: unsupported operand type(s) for +: ‘set’ and ‘set’
נוכל להוסיף ערך לקבוצה באמצעות פונקציה ייעודית: הפונקציה add. היא מקבלת ערך שאינו אוסף ושאי אפשר לשנותו במקום ומוסיפה אותו לקבוצה:
newSet = {‘blue’, ‘red’, ‘green’}
newSet.add(‘yellow’)
print(newSet)
>>>
{‘red’, ‘green’, ‘yellow’, ‘blue’}
newSet = {‘blue’, ‘red’, ‘green’}
newSet.add((‘black’, ‘yellow’))print(newSet)
>>>
{‘blue’, ‘green’, ‘red’, (‘black’, ‘yellow’)}
בהוראת ההוספה אנו כותבים את שמו של אובייקט הקבוצה, נקודה, וזימון הפונקציה add. תנו גם דעתכם שהפונקציה add משנה את הקבוצה במקום. מכאן יוצא שאין צורך לקלוט ערך החזרה מהפונקציה add (וממילא גם לא לשים אותה בצד ימני של הוראת השמה).
דוגמה נוספת לשימוש בפונקציה add:
letters = [‘b’, ‘l’, ‘u’, ‘e’]
mySet = set()
for letter in letters:
mySet.add(letter)
print(mySet)
>>>
{‘l’, ‘u’, ‘e’, ‘b’}
תנו דעתכם שקטע הקוד בדוגמה ערוך לפי התבנית הזאת:
(1) הגדרת קבוצה ריקה
(2) הוספת ערכים לקבוצה מתוך אוסף ערכים אחר – ערך אחר ערך, לפי הסדר.
התבנית הזאת מוכרת לנו: זו תבנית דומה לתבנית שעל פיה ערוכים קטעי קוד שאפשר לקצרם באמצעות List comprehension (ראו פרק ששי, סעיף 11). ואמנם גם את הקוד בדוגמה כאן אפשר לקצר, באמצעות שיטת כתיבה המכונה set comprehension. אופן הכתיבה זהה לגמרי לכתיבה של list comprehension, חוץ מהסוגריים התוחמים את הביטוי: כאן הם סוגריים מתולתלים ולא סוגריים מרובעים. הנה כך נכתוב בקיצור את קטע הקוד האחרון:
letters = [‘b’, ‘l’, ‘u’, ‘e’]
mySet = {letter for letter in letters}
print(mySet)
>>>
{‘b’, ‘e’, ‘l’, ‘u’}
נשוב להוספת ערכים לקבוצה. כאמור קבוצה לא יכולה להכיל ערך שאפשר לשנותו במקום. נסיון להוסיף ערך מסוג זה באמצעות הפונקציה add יוליך להודעת שגיאה. דוגמות:
mySet = set()
mySet.add([‘blue’, ‘green’, {‘red’, ‘yellow’}])
>>>
mySet.add([‘blue’, ‘green’, {‘red’, ‘yellow’}])
TypeError: unhashable type: ‘list’
mySet = set()
mySet.add([[]])
>>>
mySet.add([[]])
TypeError: unhashable type: ‘list’
בדוגמה הראשונה ניסינו ליצור קבוצה מרשימה הכוללת קבוצה. נסיון זה לא עלה יפה הואיל ואפשר לשנות קבוצה במקום. בדוגמה השנייה העברנו לפונקציה add רשימה שיש בה ערך אחד מסוג רשימה. על אף שרשימה פנימית זו היא ריקה, היא עדיין אוסף שאפשר לשנותו במקום, ולכן קבוצה אינה יכולה להכילו.
גם אי אפשר להוסיף לקבוצה אוסף שאי אפשר לשנותו במקום המכיל ערך שאפשר לשנותו במקום, לדוגמה רשומה המכילה רשימה:
newSet = {‘blue’, ‘red’, ‘green’}
newSet.add(([‘black’, ‘yellow’]))
print(newSet)
>>>
newSet.add(([‘black’, ‘yellow’]))
TypeError: unhashable type: ‘list’
נעיר לסיום כי אפשר למזג קבוצה אחת בקבוצה אחרת במקום באמצעות הפונקציה update ואפשר להסיר ערכים מקבוצה באמצעות הפונקציה remove. בספר זה לא נדון בפונקציות הללו.
(9) הסרת כפילויות
בסעיף הקודם הסברנו מהי קבוצה וכיצד ליצור אותה. ואולם טרם הסברנו מדוע נשתמש דווקא בקבוצה כדי לבצע את הפעולות הנדרשות על רשימות הצבעים colors2019 ו-colors2020, כלומר הוצאת כפילויות משתי הרשומות, ואיתור הצבעים ברשימה colors2020 שאינם נמצאים ברשימה colors2019. עתה ניתן את הסיבות לכך.
נפתח בהסרת הכפילויות. לקבוצה יש תכונה ההופכת אותה לאמצעי יעיל להסרת כפילויות מאוסף ערכים: בקבוצה ערך אינו יכול להופיע יותר מפעם אחת. כך למשל הקבוצה הזאת אינה יכולה להתקיים:
{‘blue’, ‘blue’, ‘red’, ‘green’}
אם ניצור קבוצה באמצעות הפונקציה set, וניתן לה אוסף של ערכים – מחרוזת, רשימה או רשומה – שיש בו כפילויות, הרי כפילויות אלו יוסרו בהמרת האוסף לקבוצה. דוגמות:
newSet = set([‘blue’, ‘blue’, ‘red’, ‘red’, ‘green’])
print(newSet)
>>>
{‘green’, ‘blue’, ‘red’}
newSet = set((‘blue’, ‘red’, ‘green’, ‘green’, ‘green’))
print(newSet)
>>>
{‘green’, ‘blue’, ‘red’}
newSet = set(‘green’)
print(newSet)
>>>
{‘g’, ‘r’, ‘e’, ‘n’}
אם נשתמש בפונקציה add לשם הוספת ערך לקבוצה, ונוסיף ערך שכבר קיים בקבוצה, הקבוצה לא תשתנה. דוגמה:
newSet = {‘blue’, ‘red’, ‘green’}
newSet.add(‘blue’)
print(newSet)
>>>
{‘red’, ‘green’, ‘blue’}
דוגמה נוספת:
letters = [‘a’, ‘b’, ‘c’, ‘a’, ‘b’]
mySet = set()
for letter in letters:
mySet.add(letter)
print(mySet)
>>>
{‘b’, ‘c’, ‘a’}
שני הזימונים האחרונים של הפונקציה add בקוד זה ניסו להוסיף לקבוצה mySet תווים שכבר הוספו לה – ‘a’ ו-‘b’ – ולכן לא שינו את הקבוצה.
מן האמור כבר מתברר כיצד נוכל להוציא כפילויות מרשומות הצבעים colors2019 ו-colors2020. כל שעלינו לעשות הוא לתת רשומות אלה לפונקציות set :
colors2019Set = set(colors2019)
colors2020Set = set(colors2020)
print(colors2019Set)
print(colors2020Set)
>>>
{‘red’, ‘yellow’, ‘brown’, ‘blue’}
{‘green’, ‘black’, ‘white’, ‘blue’}
השם ‘blue’ הופיע פעמיים ברשימה colors2019. בקבוצה colors2019Set הוא מופיע פעם אחת. השם ‘white’ הופיע פעמיים ברשימה colors2020. בקבוצה colors2020Set הוא מופיע פעם אחת.
אם כן עתה יש בידינו, בשתי קבוצות – colors2019Set ו-colors2020Set – אוספים של שמות הצבעים בלי כפילויות. באמצעות קבוצות אלו נוכל לבצע את הצעד הבא בתכנית שאנו כותבים, הווה אומר מציאת שמות הצבעים שהיו למכוניות שנמכרו בשנות 2020 ולא היו למכוניות שנמכרו בשנת 2019. גם כאן נסתייע בפעולות המוגדרות בקבוצות.
(10) השוואה בין אוספי ערכים
נוסף להסרת כפילויות יש לשמירת נתונים בקבוצה מטרה עיקרית אחרת: השוואה בין אוספי ערכים. ההשוואות הללו הן תמיד בין שתי קבוצות והן משני סוגים: יצירת קבוצה חדשה לפי חיתוך של ערכים בשתי הקבוצות או איחוד של ערכים אלה, ובדיקת הכלה של קבוצה אחת בקבוצה אחרת. נדגים את שני סוגי הפעולות באמצעות הקבוצות שיצרנו בסעיף הקודם, colors2019Set, ו-colors2020Set.
(10.1) חיתוכים ואיחודים
החסרת קבוצה מקבוצה – האופרטור –
דוגמה:
minusSet = colors2020Set – colors2019Set
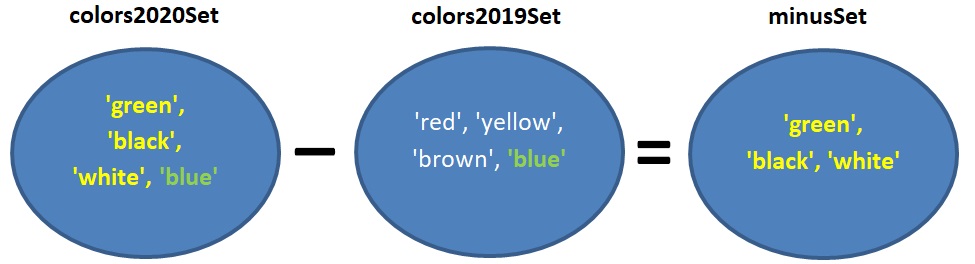
האופרטור – (חיסור) מקבל קבוצה א’ וקבוצה ב’, ומחזיר קבוצה ג’ הכוללת את כל האיברים בקבוצה א’ שאינם מופיעים בקבוצה ב’. כאן הקבוצה minusSet תכיל שמות של צבעים שהיו למכוניות שנמכרו בשנת 2020 אך לא היו למכוניות שנמכרו בשנת 2019. זו בדיוק הקבוצה שאנו נזקקים לה בתכנית צבעי המכוניות שאנו כותבים.
חיתוך קבוצה בקבוצה – האופרטור &
דוגמה:
andSet = colors2020Set & colors2019Set
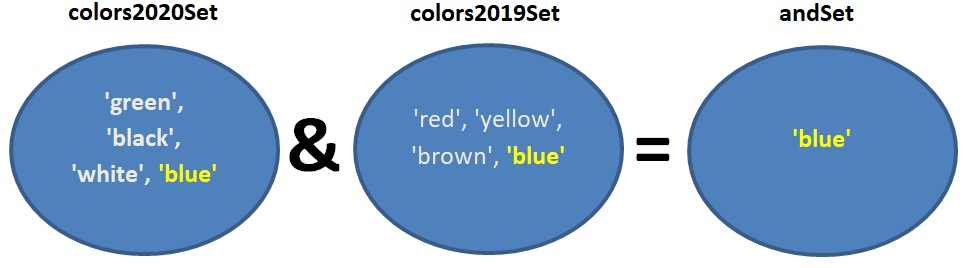
האופרטור & מקבל קבוצה א’ וקבוצה ב’, ומחזיר קבוצה ג’ הכוללת את כל האיברים המופיעים בקבוצה א’ וגם בקבוצה ב’. כאן הקבוצה andSet תכיל את שמות הצבעים שהיו למכוניות שנמכרו בשנת 2020 וגם למכוניות שנמכרו בשנת 2019.
איחוד קבוצות – האופרטור |
(הסימן | מתקבל מצירוף המקשים \+SHIFT)
דוגמה:
orSet = colors2020Set | colors2019Set
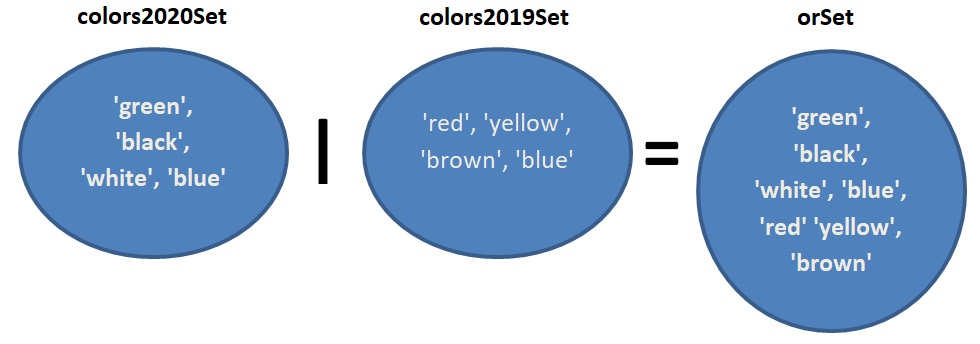
האופרטור | מקבל קבוצה א’ וקבוצה ב’, ומחזיר קבוצה ג’ הכוללת את כל האיברים המופיעים בקבוצה א’ או בקבוצה ב’. כאן הקבוצה orSet תכיל את כל שמות הצבעים (ללא כפילויות, כמובן) – הן של מכוניות שנמכרו בשנת 2020 הן של מכוניות שנמכרו בשנת 2019.
הפרש סימטרי – האופרטור ^
(הסימן ^ מתקבל מצירוף המקשים SHIFT+6)
דוגמה:
xorSet = colors2020Set ^ colors2019Set
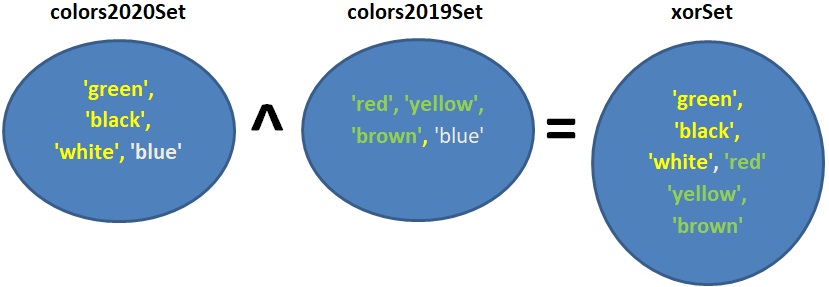
האופרטור ^ מקבל קבוצה א’ וקבוצה ב’, ומחזיר קבוצה ג’ הכוללת את כל האיברים המופיעים בקבוצה א’ או בקבוצה ב’, אך לא בשתיהן. כאן הקבוצה xorSet תכיל את כל שמות הצבעים שהיו למכוניות שנמכרו בשנת 2020 ולא היו למכוניות שנמכרו בשנת 2019, או היו למכוניות שנמכרו בשנת 2019 ולא היו למכוניות שנמכרו בשנת 2020.
נעיר כי אפשר לבצע את פעולות החיתוך והאיחוד שהוסברו לעיל גם באמצעות כמה פונקציות שלא נדון בהן כאן, והן difference, union, intersection ו-symmeteric-difference.
(10.2) בדיקת הכלה של קבוצה אחת בקבוצה אחרת
שימוש בקבוצה מקל גם על בדיקה אם אוסף אחד מוכל באוסף אחר. בביצוע בדיקה מסוג זה נשתמש בסימני ההשוואה המוכרים לנו מכתיבת ביטויים לוגיים: <, =<, >, =>, ==, =! . כל אחד ואחד מסימנים אלה מופעל על שתי קבוצות ובודק אם קיים יחס הכלה מסוים בין שתיהן. הוא מחזיר True או False לפי תוצאת הבדיקה.
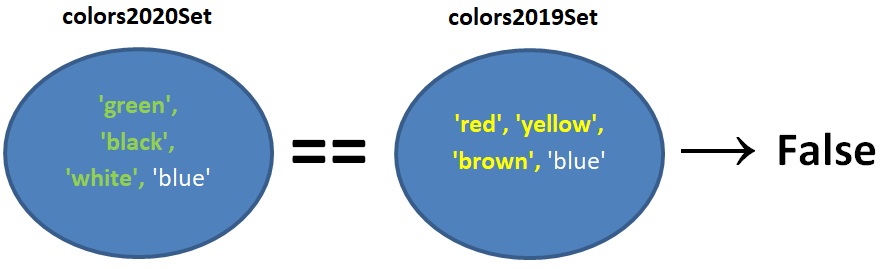
האופרטור ==
דוגמה:
colors2020Set == colors2019Set
השאלה הנבדקת: האם שמות הצבעים בקבוצה colors2020Set הם ורק הם בדיוק השמות המופיעים בקבוצה colors2019Set, כלומר האם כל הצבעים שהיו למכוניות שנמכרו בשנת 2020, ורק הם, היו למכוניות שנמכרו בשנת 2019?
האופרטור =!
דוגמה:
colors2020Set != colors2019Set
השאלה הנבדקת: האם יש שמות צבעים בקבוצה colors2020Set שאינם מופיעים בקבוצה colors2019Set, או להפך, כלומר האם בשנת 2020 היו למכוניות שנמכרו צבעים שלא היו למכוניות שנמכרו בשנת 2019, ולהפך?

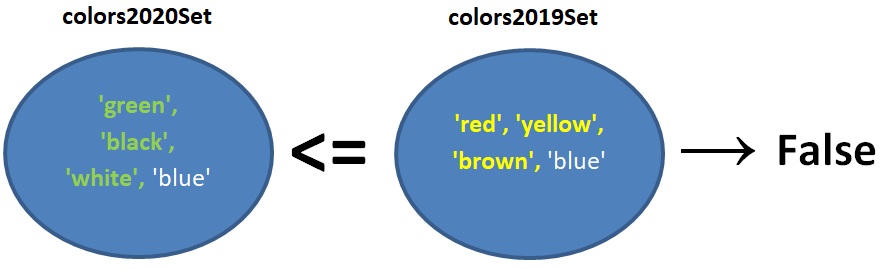
האופרטור =<, האופרטור =>
דוגמה:
colors2020Set <= colors2019Set
השאלה הנבדקת: האם כל שמות הצבעים בקבוצה colors2020Set מופיעים גם בקבוצה colors2019Set? שימו לב: הבדיקה מחזירה True גם אם שמות הצבעים בקבוצה colors2020Set הם ורק הם בדיוק השמות המופיעים בקבוצה colors2019Set.
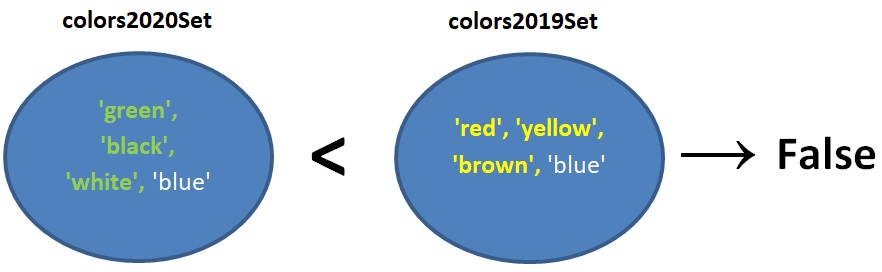
האופרטור <, האופרטור >
דוגמה:
colors2020Set < colors2019Set
השאלה הנבדקת: האם כל שמות הצבעים בקבוצה colors2020Set מופיעים גם בקבוצה colors2019Set? שימו לב: הבדיקה תחזיר False אם שמות הצבעים בקבוצה colors2020Set הם ורק הם בדיוק השמות המופיעים בקבוצה colors2019Set.
השאלה הנבדקת: האם כל שמות הצבעים בקבוצה colors2020Set מופיעים גם בקבוצה colors2019Set? שימו לב: הבדיקה תחזיר False אם שמות הצבעים בקבוצה colors2020Set הם ורק הם בדיוק השמות המופיעים בקבוצה colors2019Set.
גם הכלה של אוסף בקבוצה אפשר לבדוק באמצעות פונקציה ייעודית. שמה: issubset.
(11) השלמת התכנית – הפונקציה enumerate
בשלב זה יש בתכנית שלנו שלושה אוספים אלה (בין השאר):
• אוסף מספרי הרישוי בשנת 2020 – הרשימה liceNums2020
[‘8163919’, ‘3460905’, ‘8190097’, ‘9834579’, ‘4534544’]
• אוסף שמות הצבעים בשנת 2020, בלי כפילויות – הרשימה colors2020
[‘green’, ‘black’, ‘white’, ‘blue’]
• אוסף שמות הצבעים שהיו למכוניות בשנת 2020 ולא היו למכוניות בשנת 2019 – זו קבוצה, והיא התקבלה מהחסרת הקבוצה colors2020Set מהקבוצה colors2019Set (ראו סעיף 10.1). נכנה אותה colors2020Exclusive:
{‘green’, ‘black’, ‘white’}
בשלבה האחרון תכנית צבעי המכוניות צריכה ליצור רשימה מכל מספרי הרישוי של מכוניות שנמכרו בשנת 2020 והיו צבועות בצבעים שלא היו למכוניות שנמכרו בשנת 2019. נקרא לרשימה הזאת liceNums2020Exclusive. יצירתה היא בעיה דומה לבעיה שדנו בה בפרק הרביעי: סריקת אינדקסים של אוסף אחד ושימוש באינדקסים האלה לשם גישה לאוסף אחר השווה בגודלו לאוסף הראשון (ראו שם, סעיף 6.4). במקרה שלפנינו האוספים שווי הגודל הם הרשימות liceNums2020 ו- colors2020. אנו רוצים לסרוק אינדקס אחר אינדקס ברשימה colors2020. אם באינדקס הנוכחי מופיע צבע המוכל בקבוצת הצבעים הייחודיים colors2020Exclusive, ניגש באמצעות אינדקס זה לערך – כלומר מספר הרישוי – המקביל ברשימה liceNums2020, ונוסיף מספר זה לרשימת מספרי הרישוי liceNums2020Exclusive, כפי שממחיש התרשים הזה:
אם כן נוכל לכתוב כך:
liceNums2020Exclusive = []
for i in range(len(colors2020)):
if colors2020[i] in colors2020Exclusive:
liceNums2020Exclusive.append(liceNums2020[i])
print(liceNums2020Exclusive)
>>>
[‘8163919’, ‘3460905’, ‘8190097’, ‘4534544’]
הקוד מתחיל ביצירת הרשימה liceNums2020Exclusive. הרשימה מתחילה את חייה בתור רשימה ריקה, ועד לסוף ביצוע קטע הקוד תכיל את מספרי הרישוי של מכוניות שנמכרו בשנת 2020 והיו צבועות בצבעים המופיעים ברשימה colors2020Exclusive. הלולאה סורקת את האינדקסים של רשימת הצבעים של מכוניות שנמכרו בשנת 2020. אם באינדקס הנוכחי ברשימה יש צבע המופיע ברשימה colors2020Exclusive נעשה שימוש באינדקס הזה כדי לגשת למספר הרישוי המתאים ברשימה liceNums2020.
אפשר לכתוב את קטע הקוד האחרון באופן מעט מובן יותר מזה באמצעות הפונקציה enumerate. הפונקציה enumerate מקבלת רצף ומפיקה מבנה נתונים שיש בו רשומות שמספרן שווה למספר הערכים ברצף. כל רשומה מכילה שני איברים: האינדקס של הערך ברצף, והערך, בסדר זה. דוגמה:
colors2020 = [‘green’, ‘black’, ‘white’, ‘blue’]
for item in enumerate(colors2020):
print(item)
>>>
(0, ‘green’)
(1, ‘black’)
(2, ‘white’)
(3, ‘blue’)
הפונקציה enumerate מקבלת כאן את הרשימה colors2020 ולולאת ה-for סורקת איברים במבנה שהפונקציה מחזירה. בכל סיבוב של הלולאה ההוראה בגוף הלולאה מדפיסה את האיבר הנוכחי. כפי שאפשר לראות כל איבר במבנה שהפונקציה enumerate החזירה מכיל שני ערכים: השני הוא ערך ברשימה colors2020, ואילו הראשון הוא אינדקס של הערך הזה ברשימה colors2020.
באמצעות השמה מרובה נוכל לפרק את הערכים בכל רשומה במבנה enumerate ולהציבם בשני משתנים:
colors2020 = [‘green’, ‘black’, ‘white’, ‘blue’]
for i, color in enumerate(colors2020):
print(i, color)
>>>
0 green
1 black
2 white
3 blue
כאן פירקנו כל רשומה במבנה שיוצרת enumerate לשני משתנים – האינדקס למשתנה i, והערך – שם הצבע – למשתנה color. הוראת ההדפסה בגוף הלולאה מדפיסה ערכים אלה.
כשיש בידינו הן הערך ברשימה colors2020 הן האינדקס שלו, נוכל לכתוב פתרון לבעיית הערכים המקבילים השווים שהוא מובן ופשוט יותר מהפתרון הקודם:
liceNums2020Exclusive = []
for i, color in enumerate(colors2020):
if color in colors2020Exclusive:
liceNums2020Exclusive.append(liceNums2020[i])
print(liceNums2020Exclusive)
>>>
[‘8163919’, ‘3460905’, ‘8190097’, ‘4534544’]
כאן, בכניסה לגוף הלולאה, יש בידינו הן צבע מהרשימה colors2020 (במשתנה color) הן האינדקס של הצבע הזה ברשימה (במשתנה i). הצבע משמש בתנאי הנבדק בהוראת ה-if: ביטוי זה בודק אם הצבע נמצא ברשימה colors2020Exclusive, רשימת הצבעים שהיו למכוניות שנמכרו בשנת 2020 ולא היו למכוניות שנמכרו בשנת 2019. השתמשנו באינדקס כדי לגשת למספר הרישוי הנמצא באינדקס זה ברשימת מספרי הרישוי liceNums2020.
זו אפוא תכנית המכוניות המלאה:
# (1) Saving data in tuples.
f = open(‘colors2019.txt’, ‘r’)
s = f.read()
lines = s.split(‘\n’)
liceNumsAndColors2019 = ()
for line in lines:
liceNumsAndColors2019 = liceNumsAndColors2019 + (tuple(line.split()),)
f.close()
f = open(‘colors2020.txt’, ‘r’)
s = f.read()
lines = s.split(‘\n’)
liceNumsAndColors2020 = ()
for line in lines:
liceNumsAndColors2020 = liceNumsAndColors2020 + (tuple(line.split()),)
f.close()
# (2) Separating liceNums from colors.
liceNums2019 = []
colors2019 = []
for liceNum, color in liceNumsAndColors2019:
liceNums2019.append(liceNum)
colors2019.append(color)
liceNums2020 = []
colors2020 = []
for liceNum, color in liceNumsAndColors2020:
liceNums2020.append(liceNum)
colors2020.append(color)
# (3) Converinng color lists to sets,
# thus eliminating duplicates,
# and producing a set of colors
# of cars sold in 2020 yet not
# of cars sold in 2019.
# Finally, producing the desired list
# of license numbers.
colors2019Set = set(colors2019)
colors2020Set = set(colors2020)
colors2020Exclusive = colors2020Set – colors2019Set
liceNums2020Exclusive = []
for i, color in enumerate(colors2020):
if color in colors2020Exclusive:
liceNums2020Exclusive.append(liceNums2020[i])
(12) סיכום
בפרק זה עסקנו ברשומה ובקבוצה והתמקדנו בשימושים המעשיים בסוגי אוספים אלה. ראינו כי רשומה משמשת לשמירת ערכים מסוגים מגוונים באוסף שאין כוונה לשנותו, וכי היא סוג של אוסף המתאים לשמירת שורה אחת או תצפית אחת במסד נתונים. בכל הנוגע לקבוצה עיינו ביכולת להסיר באמצעותה כפילויות מאוסף בקלות, וגם להשוות בין אוספים. הטיפול ברשומה ובקבוצה, הוא מגוון ועשיר יותר ממה שראינו כאן, ועד לסוף הספר ניווכח בכך, בייחוד במה שקשור לרשומה. כפי שנראה רשומה היא רכיב חשוב הן בטיפול במילונים הן בזימוני פונקציות.