פרק חמישי
מבוא לרצפים (ב)

תוכן העניינים
(2) בדיקת אי-ריקות ובדיקת ריקות
(3) האם הערך מופיע ברצף או אינו מופיע בו – האופרטורים in ו-not in
(4) ערך מינימלי, ערך מקסימלי וסכום – הפונקציות min, max ו-sum
(5) מספר הופעות של ערך – הפונקציה count
(6) אינדקס של תת-רצף – הפונקציות index ו-find
(7) צירוף והכפלה – האופרטורים + ו-*
הוראות המופיעות בגוף של מבנה while ומתבצעות כל עוד תנאי הלולאה מתקיים צריכות להיות מוזזות ימינה ביחס לשורה הראשונה במבנה. הקוד התקין:
age = input(‘Insert age; -1 to stop: ‘)
while age != ‘-1’:
print(age)
age = input(‘Insert age; -1 to stop: ‘)
(1) מבוא
בקרב מתכנתות ומתכנתים רבים יצא לפייתון שם של שפת תכנות שימושית מאוד, גמישה ומלהיבה. סיבה אחת חשובה למוניטין זה נוגעת לטיפול באוספי ערכים. בפייתון טיפול באוספים הוא לא פעם פשוט יותר מהטיפול בהם בשפות אחרות. לשם דוגמה: נניח שעלינו למצוא כמה ערכים ברצף שווים לערך נתון, או למצוא סכום של מספרים ברצף נתון, או למצוא את הערך המקסימלי ברצף נתון. בפרק הרביעי (סעיף 3) ראינו תבניות המשמשות בכתיבת תכניות הפותרות בעיות כאלו. כל התבניות הללו הסתמכו על סריקה של רצפים באמצעות לולאה. במקרים רבים כשנבוא לכתוב תכניות הבאות לפתור בעיות כמו אלו הנזכרות, נוכל להשתמש בפונקציות המובנות בשפה, מייתרות את השימוש בלולאה, מקצרות את התכנית ומפשטות אותה. זאת ועוד: בפייתון, כמו בשפות תכנות אחרות, יש פעולות המטפלות באוספים של ערכים והן חלק מליבת השפה, ויש פעולות המטפלות באוספי ערכים שביצוען דורש ייבוא של קוד (ממש כשם שאנו מייבאים את המודול random כדי להשתמש בפונקציות המטפלות במספרים אקראיים – ראו סעיף 8 בפרק הראשון). ואולם מִצד הטיפול באוספים פייתון גם מתייחדת משפות אחרות: מגוון הפעולות שהיא מאפשרת לבצע באוספים כחלק מליבת השפה, כמו גם מגוון מבני הנתונים (data structures) שהיא מאפשרת להשתמש בהם לשמירת אוספים, גם כן כחלק מליבתה, הם עשירים יותר ממה שמציעות שפות תכנות חשובות אחרות. העוצמה שיש לפייתון בטיפול באוספים גלומה בין השאר בפעולות ברצפים. בפרק הנוכחי נמשיך את הדיון בפעולות אלו.
(2) בדיקת אי-ריקות ובדיקת ריקות
כיצד נבדוק אם רצף אינו ריק, וספציפית אם יש במחרוזת תווים או אם יש ברשימה ערכים? שיטת בדיקה אחת משתמשת בפונקציה len. דוגמות:
s = ‘nothing new’
if (len(s) > 0):
print(‘String is not empty.’)
>>>
String is not empty.
lst = []
if (len(lst) > 0):
print(‘List is not empty.’)
>>>
בשיטת בדיקה אחרת הביטוי הלוגי מתקצר, וכלל אינו משתמש בפונקציה len. הוא מכיל את שם הרצף בלבד. דוגמות:
s = ‘nothing new’
if s:
print(‘String is not empty.’)
>>>
String is not empty.
lst = []
if lst:
print(‘List is not empty.’)
>>>
השאלה “האם מחרוזת?” מתפרשת כמו השאלה “האם המחרוזת אינה ריקה?”, והשאלה “האם רשימה?” מתפרשת כמו השאלה “האם הרשימה אינה ריקה?”. דיון נוסף בהגיון העומד בבסיס כתיבה מקוצרת זו מוסבר בנספח ח’.
כדי לבדוק ריקות של רצף נניח את האופרטור not לפני שם הרצף בביטוי הלוגי. דוגמות:
s = ‘nothing new’
if not s:
print(‘String is empty.’)
>>>
lst = []
if not lst:
print(‘List is empty.’)
>>>
List is empty.
השאלה “האם לא מחרוזת?” מתפרשת כמו השאלה “האם המחרוזת ריקה?”, והשאלה “האם לא רשימה?” מתפרשת כמו השאלה “האם הרשימה ריקה?”.
(3) האם ערך מופיע ברצף או אינו מופיע בו – האופרטורים in ו-not in
נתונה בעיה זו: יש לבדוק אם ערך נתון מופיע ברצף נתון. בפתרונה אפשר לסרוק את הרצף הנתון, ולבדוק עבור כל ערך בו אם הוא שווה לערך הנתון. אך יש דרך פשוטה יותר לביצוע הבדיקה: שימוש באופרטור in . נכתוב את הבדיקה באמצעות ביטוי לוגי הבנוי בתבנית זו:
value in sequence
כלומר: הערך שאנו רוצים לבדוק את קיומו ברצף, האופרטור in, ושם הרצף. נבהיר את הדברים באמצעות עיון בשתי דוגמות. בשתיהן נעשה שימוש באופרטור in בכתיבת ביטוי לוגי הנבדק בהוראת if. בדוגמה הראשונה התנאי מתקיים, ובדוגמה השניה התנאי אינו מתקיים:
s = ‘I am here.’
c = ‘a’
if c in s:
print(‘The sequence includes the value:’, c)
>>>
The sequence includes the value: a
seasons = [‘winter’, ‘spring’, ‘summer’, ‘autumn’]
season = ‘Winter’
if season in seasons:
print(‘The sequence includes the value:’ season)
>>>
תנו דעתכם: בדוגמה השנייה יש בדיקה – האם המחרוזת ‘Winter’ נמצאת ברשימה seasons – והבדיקה מחזירה False. הסיבה היא שברשימה אין מופיעה המחרוזת ‘Winter’ אלא המחרוזת ‘winter’. ככלל כדי שתוצאת הביטוי הנבנה באמצעות האופרטור in תהיה True הרצף צריך להכיל בדיוק את הערך שהביטוי מחפש.
אם נחפש באמצעות האופרטור in ערך המופיע בתוך רשימה הכלולה ברשימה ולא מחוץ לרשימה הפנימית החיפוש יחזיר False. דוגמה:
lst = [‘1st’, [‘winter’, ‘spring’, ‘summer’, ‘autumn’]]
season = ‘Winter’
if season in lst:
print(‘The sequence includes the value:’, season)
>>>
כאן החיפוש הוא ברשימה שיש בה שני ערכים – המחרוזת ‘1st’ ורשימה של מחרוזות – ואף לא אחד מהם הוא המחרוזת ‘Winter’. לכן אין מתבצעת הוראת ההדפסה.
נשתמש באופרטור not in כדי לבדוק אם ערך מסוים אינו מופיע ברצף. דוגמות:
s = ‘I am here.’
c = ‘a’
if c not in s:
print(‘The value: ‘, c, ‘, does not appear in the sequence’)
>>>
seasons = [‘winter’, ‘spring’, ‘summer’, ‘autumn’]
season = ‘Winter’
if season not in seasons:
print(‘The value: ‘, season, ‘, does not appear in the sequence’)
>>>
The value: Winter , does not appear in the sequence
(4) ערך מינימלי, ערך מקסימלי וסכום – הפונקציות max ,min ו-sum
גם במציאת ערך מקסימלי ברצף, ערך מינימלי ברצף וסכום של מספרים ברצף נוכל להשתמש בתבניות המבוססות על סריקת הרצף בלולאה, ואולם במקרים רבים נוכל להשתמש בפונקציות המוגדרות בליבת השפה.
הפונקציה min מקבלת רצף ומחזירה את הערך המינימלי בו. הפונקציה max מקבלת רצף ומחזירה את הערך המקסימלי בו. הנה דוגמות להפעלת פונקציות אלו על רשימה:
lst = [5, 2, 9]
print(min(lst))
>>
2
lst = [5, 2, 9]
print(max(lst))
>>
9
בהפעלת הפונקציות min ו-max על מחרוזות, המינימום והמקסימום נקבעים לפי סדר המילון, ואותיות אנגליות ב-upper case (אותיות “גדולות”) קודמות לאותיות ב-lower case (אותיות “קטנות”). דוגמות:
minimum = min(‘abc’)
print(minimum)
>>>
a
maximum = max(‘aAbB’)
print(maximum)
>>>
b
רשימות המועברות בתור ארגומנטים לפונקציה min ו-max יכולות להכיל רק מחרוזות או רק מספרים, אך לא שילוב ביניהם. עיינו בדוגמה זו:
maximum = max([-1, -1, -1, -1, “a”])
print(maximum)
>>>
maximum = max([-1, -1, -1, -1, “a”])
TypeError: ‘>’ not supported between instances of ‘str’ and ‘int’
בין מחרוזות למספרים (כאן: מספרים שלמים) אין מוגדר יחס של השוואה, ולכן אין משמעות למציאת מקסימום (או מינימום) ברשימה המעורבת ממחרוזות וממספרים.
הפונקציה sum מקבלת רצף של מספרים, מחשבת את סכום המספרים ברצף, ומחזירה אותו. דוגמה:
lst = [1, -1, 1, -1, 1, -1]
print(sum(lst))
>>>
0
מה יקרה אם נעביר לפונקציה sum מחרוזת המייצגת מספר, כגון המחרוזת ‘5432’? האם הפונקציה sum תחשב את סכום הספרות במספר? עיינו בקוד הזה ובפלט של הרצתו:
print(sum(‘5432’))
>>>
print(sum(“5432”))
TypeError: unsupported operand type(s) for +: ‘int’ and ‘str’
אמנם מחרוזת היא רצף, ובכל זאת הפעלת הפונקציה sum על מחרוזת, ובייחוד על מחרוזת המכילה רק תווי ספרות, גורמת לשגיאת הרצה. מבחינה זו העיון בפונקציה sum חורג במידת מה מהדיון בפרק הנוכחי.
(5) מספר הופעות של ערך – הפונקציה count
כדי לספור כמה פעמים ערך נתון מופיע ברצף נתון, נוכל להשתמש בלולאה הערוכה בתבנית מניה. ואולם פייתון מעמידה לרשותנו מן המוכן פונקציה מתאימה המשוכללת יותר ממימוש התבנית. זו הפונקציה count.
הדבר הראשון שעלינו לתת עליו את הדעת כשאנו באים להשתמש בפונקציה count הוא שתחביר הזימון שלה הוא מעט שונה מתחביר הזימון של רוב הפונקציות שראינו עד כה, ודומה לזימון של הפונקציה randint שפגשנו בפרק הראשון (סעיף 8). בזימון הפונקציה count נכתוב את שם המחרוזת או שם הרשימה שאנו באים לספור איברים בה, ואחריו נקודה, ואחריה שם הפונקציה, כלומר count. הפונקציה count תקבל בתור ארגומנט את הערך שאנו רוצים לספור את מספר הופעותיו ברצף. דוגמה:
info = [“Yasmin Levy”, 43, “Psychology”, 3]
result = info.count(3)
print(result)
>>>
1
בדוגמה זו כתבנו לפני שם הפונקציה count את שם הרצף – כאן: הרשימה – שאנו מעוניינים לספור בה, ונקודה. בתור ארגומנט לפונקציה count נתנו את המספר 3. הפונקציה סופרת כמה פעמים המספר 3 מופיע ברשימה lst, מחזירה את התוצאה 1, והתוצאה הזאת מוצבת במשתנה result.
בהפעלת הפונקציה count על מחרוזת, החיפוש הוא אחר תת-מחרוזות. דוגמה:
s = ‘the whole of the moon’
result = s.count(‘the’)
print(result)
>>>
2
כאן הפונקציה count מחפשת כמה פעמים המחרוזת ‘the’ מופיעה במחרוזת המוצבת במשתנה s, ומוצאת כי היא מופיעה פעמיים. תנו דעתכם כי בזימון הפונקציה count כתבנו לפני שם הפונקציה את שם המחרוזת שאנו רוצים לחפש בה ונקודה.
אם הפונקציה count לא מוצאת כלל את הערך שחיפשה, היא מחזירה 0. דוגמה:
lst = [-5, -4, -3, -2, -1]
result = lst.count(-8)
print(result)
>>>
0
הואיל והערך 8- אינו מופיע ברשימה lst, הפונקציה count החזירה 0.
(6) אינדקס של תת-רצף – הפונקציות index ו-find
אם נרצה למצוא את האינדקס שערך נתון מופיע לראשונה ברצף נתון, נוכל לכתוב לולאה הסורקת את האינדקסים המוגדרים ברצף, ומאתרת את האינדקס שמופיע בו הערך הנתון (להדגמה ראו סעיף 6.4 בפרק הקודם). אך גם כאן נעדיף להשתמש בפונקציות המוגדרות בליבת השפה. אחת מהן היא הפונקציה index. כמו הפונקציה count גם הפונקציה index מזומנת באמצעות אובייקט הרצף שהיא מחפשת בו. דוגמה:
info = [“Yasmin Levy”, 43, “Psychology”, 3, 3]
ind = info.index(3)
print(ind)
>>>
3
בדוגמה זו כתבנו לפני שם הפונקציה index את שם הרצף – כאן: הרשימה – שאנו מעוניינים למצוא בו ערך, ונקודה. בתור ארגומנט לפונקציה index נתנו את המספר 3. הפונקציה תמצא את ההופעה הראשונה של המספר 3 ברשימה info, תחזיר את התוצאה (האינדקס) 3, והתוצאה הזאת תוצב במשתנה ind.
דוגמה נוספת:
s = ‘The whole of the moon’
ind = s.index(‘the’)
print(ind)
>>>
13
כאן הפונקציה index מוצאת שהמחרוזת ‘the’ מופיעה לראשונה באינדקס 13 במחרוזת המוצבת במשתנה s. היא מחזירה מספר זה והוא מוצב במשתנה ind.
אם הפונקציה index אינה מוצאת את הערך שהיא מחפשת, התכנית נפסקת ומוצאת הודעת שגיאה. דוגמה:
s = ‘The whole of the moon’
ind = s.index(‘missing’)
print(ind)
>>>
ind = s.index(‘missing’)
ValueError: substring not found
אפשר להעביר לפונקציה index ארגומנט שני הקובע את האינדקס שהחיפוש מתחיל בו. דוגמה:
dice = [1, 4, 2, 3, 6, 5, 4]
ind = dice.index(4, 2)
print(ind)
>>>
6
כאן החיפוש אחר המספר 4 מתחיל באינדקס 2 ברשימה dice. לכן, על אף שהמספר 4 מופיע באינדקס 1, החיפוש ימצא אותו באינדקס 6, והפונקציה תחזיר אינדקס זה.
אפשר גם להעביר לפונקציה index ארגומנט שלישי הקובע את הגבול העליון של המקטע שיש לחפש בו. גבול זה הוא מספר הגדול ב-1 מהאינדקס שבו מופיע הערך האחרון במקטע שיש לחפש בו. כדי להבין במה דברים אמורים נעיין בדוגמה הזאת:
dice = [1, 4, 2, 3, 6, 5, 4]
ind = dice.index(4, 2, 6)
print(ind)
>>>
ind = dice.index(4, 2, 6)
ValueError: 4 is not in list
כאן חיפוש המספר 4 מתחיל באינדקס 2 ברשימה dice ומסתיים באינדקס 5 – כלומר מקום אחד לפני המספר הניתן בתור ארגומנט שלישי, 6. במקטע הזה של הרשימה dice אין מופיע המספר 4. לכן נגרמת שגיאה ומוּצאת הודעה על כך. דוגמה נוספת:
lst = [“”,”not empty”, “not empty”, “”]
ind = lst.index(“”, 1, 3)
print(ind)
>>>
ind = lst.index(“”, 1, 3)
ValueError: ” is not in list
המקטע של lst שהחיפוש נערך בו כאן מתחיל בערך שיש באינדקס 1 ברשימה lst ומסתיים בערך שיש באינדקס 2 – כלומר מקום אחד לפני המספר הניתן בתור ארגומנט שלישי, 3. במקטע זה אין מחרוזת ריקה, ולכן הפונקציה index מחזירה הודעת שגיאה.
אפשר להימנע בשגיאה מעין זו באמצעות בדיקה מקדימה: האם הערך לחיפוש ברצף מופיע ברצף או שאינו מופיע בו? קל לבצע בדיקה זו באמצעות האופרטורים in ו-not in. בנוסף בחיפוש במחרוזות נוכל להימנע מהודעת שגיאה כשמחרוזת לחיפוש אינה נמצאת, באמצעות שימוש בפונקציה find.
מצד התחביר השימוש בפונקציה find דומה מאוד לשימוש בפונקציה index. וגם פעולתה וערך ההחזרה שלה דומים לאלה של הפונקציה index: היא מחפשת את התו במחרוזת הנתונה שבו מופיעה לראשונה המחרוזת לחיפוש, ומחזירה את האינדקס של התו הזה. ואולם שלא כמו הפונקציה index, הפונקציה find מחזירה 1- (מינוס 1) אם המחרוזת לחיפוש אינה נמצאת במחרוזת הנתונה. דוגמה:
s = ‘find me!’
print(s.find(‘you’))
>>>
-1
כאן הפונקציה find חיפשה את המחרוזת ‘you’ בתוך המחרוזת ‘find me!’, לא מצאה אותה, והחזירה 1-.
אפשר לתת לפונקציה find ארגומנט שני – מספר המציין אינדקס של תו שהחיפוש במחרוזת הנתונה יתחיל בו. דוגמה:
s = ‘find me!’
print(s.find(‘me!’, 6))
>>>
-1
החיפוש כאן התחיל בתו המופיע באינדקס 6, כלומר בתו ‘e’, ולכן לא נמצאה המחרוזת ‘!me’.
אפשר לתת לפונקציה find גם ארגומנט שלישי – מספר המציין אינדקס של תו במחרוזת הנתונה שהחיפוש יסתיים בו; החיפוש לא יכלול תו זה ואת כל התווים אחריו. דוגמה:
s = ‘find me!’
print(s.find(‘me!’, 0, 7))
>>>
-1
כאן החיפוש החל בתחילת המחרוזת אך לא כלל את התו ‘!’.
(7) צירוף והכפלה – האופרטורים + ו-*
לפעולות שנעיין בהן עד לסופו של פרק זה יש מן המשותף: כולן יוצרות רצפים חדשים לפי רצפים קיימים. נפתח בצירוף רצפים לרצף אחד, באמצעות האופרטורים + ו-*.
נשתמש באופרטור + כדי לצרף רצף א’ לרצף ב’ בסדר זה וליצור רצף ג’ שראשיתו הערכים ברצף א’ וסופו הערכים ברצף ב’. הנה דוגמה לשימוש באופרטור לצירוף מחרוזות:
s1 = ‘first ‘
s2 = ‘second’
s3 = s1 + s2
print(s3)
>>>
first second
צירוף רשימה א’ לרשימה ב’ בסדר זה יוצר רשימה ג’ שראשיתה הערכים ברשימה א’ וסופה הערכים ברשימה ב’. דוגמה:
lst1 = [‘first’, ‘second’]
lst2 = [‘third’, ‘fourth’]
lst3 = lst1 + lst2
>>>
[‘first’, ‘second’, ‘third’, ‘fourth’]
הרצפים המצורפים זה לזה באמצעות האופרטור + הם בהכרח מסוג שווה. תוצאה חשובה של כלל זה היא שאם נרצה ליצור מחרוזת שהיא צירוף של מחרוזת ומספר נצטרך ראשית להמיר את המספר למחרוזת. דוגמה:
s = ‘It is ‘
num = 2021
print(s + str(num))
>>>
It is 2021
תנו דעתכם שחוק החילוף המוכר לכם מלימודי המתמטיקה אינו מתקיים בצירוף רצפים באמצעות האופרטור +. עיינו בקטעי קוד אלה:
s1 = ‘ab’ + ‘cd’
s2 = ‘cd’ + ‘ab’
print(s1)
print(s2)
print(s1 == s2)
>>>
‘abcd’
‘cdab’
False
lst1 = [3, 7] + [9, 5]
lst2 = [9, 5] + [3, 7]
print(lst1)
print(lst2)
print(lst1 == lst2)
>>>
[3, 7, 9, 5]
[9, 5, 3, 7]
False
אפשר גם להכפיל רצף, כלומר לשרשר אותו לעצמו מספר פעמים מסוים. נעשה זאת באמצעות האופרטור * . דוגמות:
s = ‘again -‘ * 2
print(s)
>>>
again -again –
lst = [‘the same’] * 3
print(lst)
>>>
[‘the same’, ‘the same’, ‘the same’]
הכפלה רצף במספר לא חיובי מחזירה רצף ריק (מחרוזת ריקה, רשימה ריקה). דוגמות:
s = ‘I am doomed’
newS = s * -7
print(‘-‘ + newS + ‘-‘)
>>>
—
lst = [‘Please’, ‘nullify’, ‘me’]
newLst = lst * 0
print(newLst)
>>>
[]
תנו דעתכם שחוק הפילוג אינו תקף ברצפים. דוגמות:
s1 = 2 * (‘ab’ + ‘cd’)
s2 = 2 * ‘ab’ + 2 * ‘cd’
print(s1)
print(s2)
print(s1 == s2)
>>>
‘abcdabcd’
‘ababcdcd’
False
lst1 = 2 * ([3, 7] + [9, 5])
lst2 = 2 * [9, 5] + 2 * [3, 7]
print(lst1)
print(lst2)
print(lst1 == lst2)
>>>
[3, 7, 9, 5, 3, 7, 9, 5]
[9, 5, 9, 5, 3, 7, 3, 7]
False
יש להדגיש כי הרצפים שהאופטורים + ו-* מופעלים עליהם אינם משתנים. קוד זה מדגים את הדברים:
lst = [‘old’]
newLst = lst + lst
print(lst)
>>>
[‘old’]
בתחילת הקוד הרשימה lst מכילה ערך אחד. לאחר מכן היא מצורפת לעצמה. הצירוף יוצר רשימה חדשה, ואילו הרשימה lst נשארת ללא שינוי: בסוף הקוד היא עדיין מכילה את המחרוזת ‘old’ בלבד. בהקשר זה כדאי לעיין בנספח ב’, הדן בפשרו של האופרטור =+
(8) יצירת עותק של מקטע רצף (slicing)
גם הפעולה שנדון בה עתה יוצרת רצף חדש לפי רצף קיים. ספציפית היא יוצרת עותק של מקטע רצף נתון. לדוגמה אם נתונה מחרוזת זו:
s = ‘right left right’
נוכל ליצור עותק של מקטע המחרוזת המתחיל באינדקס 6 (כולל) ומסתיים באינדקס 10 (לא כולל).
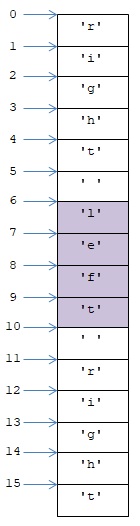
לצורך יצירת עותק המקטע נשתמש באופרטור [ ], ובאופן שונה מאופן השימוש בו ביצירת עותק של ערך אחד ברצף. הפעם בתוך הסוגריים המרובעים לא יהיה אינדקס יחיד. במקום זה נגדיר בתוכם את גבולות המקטע שאנו מעוניינים בעותק שלו. הנה התחביר הבסיסי של הגדרת גבולות המקטע:
begin : end
כלומר:
• begin – אינדקס תחילת המקטע
• נקודתיים
• end – מספר הגדול ב-1 מאינדקס סיום המקטע
דוגמה:
s = ‘right left right’
newS = s[6 : 10]
print(newS)
>>>
left
הפעלת האופרטור [ ] כאן יוצרת עותק של תת המחרוזת של מחרוזת s המתחילה בתו המופיע באינדקס 6 ומסתיימת בתו המופיע מיד לפני התו הנמצא באינדקס 10, כלומר בתו הנמצא באינדקס 9.
דוגמה נוספת:
lst = [‘only’, ‘this’, ‘word’]
print(lst[1 : 2])
>>>
[‘this’]
הפעלת האופרטור [ ] כאן יוצרת עותק של רצף הערכים ברשימה lst המתחיל בערך המופיע באינדקס 1 ומסתיים בערך המופיע לפני הערך הנמצא באינדקס 2.

יש הבדל נוסף בין הפעלת האופרטור [ ] ליצירת עותק של מקטע רצף להפעלת האופרטור [ ] ליצירת עותק של ערך אחד ברצף. כפי שראינו, כשאנו יוצרים עותק של מקטע של רשימה, התוצאה היא רשימה. לעומת זאת כשאנו יוצרים עותק של ערך אחד ברשימה, התוצאה אינה בהכרח רשימה, כפי שמדגים קטע הקוד הזה:
lst = [‘only’, ‘this’, ‘word’]
print(lst[1])
>>>
‘this’
אמנם אם יוצרים עותק של ערך אחד ברשימה, והערך הזה הוא עצמו רשימה, הפעלת האופרטור [ ] מחזירה רשימה. דוגמה:
lst = [‘only’, [‘this’], ‘word’]
print(lst[1])
>>>
[‘this’]

נפנה להתמקד באופן הכתיבה של טווח המקטע בתוך הסוגריים המרובעים. הנה שוב התחביר הבסיסי:
begin : end
אם נרצה ליצור עותק המתחיל בערך הראשון ברצף, אין צורך שנציין את begin. ואם המקטע מסתיים בערך האחרון ברצף (וכולל אותו), אין צורך לציין את end. דוגמה:
s = ‘one two three’
newS = s[:2]
print(newS)
>>>
‘on’
כאן לא כתבנו אינדקס לפני הסימן נקודתיים, כיוון שברצוננו ליצור עותק של מקטע של s המתחיל באינדקס 0.
ודוגמה על רשימה:
lst = [‘beginning’, ‘middle’, ‘end’]
print(lst[1:])
>>>
[‘middle’, ‘end’]
כאן לא כתבנו אינדקס לאחר הסימן נקודתיים, כיוון שברצוננו ליצור עותק של המקטע של הרשימה lst המסתיים בערך האחרון של הרשימה (וכולל אותו).
מן האמור יוצא כי אם כלל לא נציין את גבולות המקטע בתוך הסוגריים המרובעים, ייווצר עותק של הרצף כולו. דוגמה:
lst = [‘beginning’, ‘middle’, ‘end’]
print(lst[:])
>>>
[‘beginning’, ‘middle’, ‘end’]
אם begin >= end, ושניהם חיוביים או שניהם שליליים, מתקבל רצף ריק (מחרוזת ריקה או רשימה ריקה). דוגמות:
s = ‘no error here’
print(‘-‘ + s[5:2] + ‘-‘)
>>>
—
lst = [-7, -5]
print(lst[1:1])
>>>
[]
אם end גדול ממספר התווים ברצף או שווה לו, המקטע יסתיים בערך האחרון ברצף. דוגמה:
lst = [‘do’, ‘not’, ‘exaggerate!’]
print(lst[2:10])
>>>
[‘exaggerate!’]
אפשר להנחות את פייתון לבנות את עותק המקטע בדילוגים. במקרה זה תחביר השימוש באופרטור [ ] ישתנה – יתוספו בו נקודתיים ומספר שלם אחריהם, כך:
begin : end : step
step – גודל הדילוג. הוא בהכרח שונה מ-0.
דוגמה:
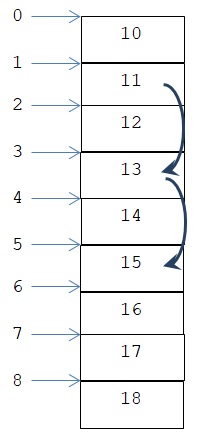
lst = [10, 11, 12, 13, 14, 15, 16, 18]
oddNums = lst[1:7:2]
print(oddNums)
>>>
[11, 13, 15]
בדוגמה זו הערך באינדקס 1 ברשימה הנתונה, כלומר המספר 11, הוא הערך הראשון ברשימה החדשה. כיוון ש- step == 2, הערך השני ברשימה החדשה הוא הערך באינדקס 3 (התוצאה של הוספת גודל הצעד 2 לאינדקס שהתחלנו בו, 1) ברשימה הנתונה, כלומר המספר 12, מכאן מתבצע דילוג מהערך באינדקס 3 לערך באינדקס 5, וכך מתוסף לרשימה החדשה המספר 15. דילוג מכאן לאינדקס 7 חורג מגבול המקטע שהוגדר, כי הרי end = 7, ופירוש הדבר שהמקטע אמור להסתיים באינדקס 6.
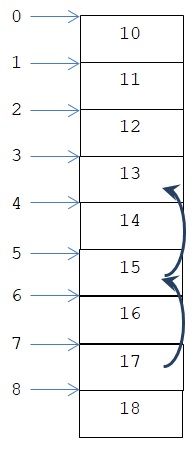
step שלילי פירושו דילוג לאחור. דוגמה:
lst = [10, 11, 12, 13, 14, 15, 16, 17, 18]
oddNums = lst[7:1:-2]
print(oddNums)
>>>
[17, 15, 13]
בהקשר הנוכחי ראוי לציין שימוש שכיח בציון גודל הדילוג – שימוש שמטרתו להפוך את הרצף. הנה דוגמות לשימוש זה:
s = ‘abc’
newS = s[::-1]
print(newS)
>>>
cba
lst = [3, 2, 1]
newLst = lst[::-1]
print(newLst)
>>>
[1, 2, 3]
בשתי הדוגמות לא ציינו בתוך הסוגריים המרובעים גבול עליון וגבול תחתון למקטע, ופירוש הדבר שה”חיתוך” יבוסס על הרצף כולו (המחרוזת או הרשימה). דילוג בגודל 1- (מינוס 1) פירושו שיש לסרוק את כל הרצף החל מסופו ועד לתחילתו. כך ייוצר רצף חדש, שהערכים בו מסודרים בסדר הפוך לסדרם ברצף המקורי.
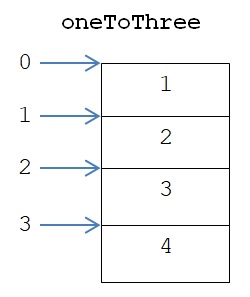
נציין כי אפשר להפעיל את האופרטור [ ] גם על רצף שיוצרת הפונקציה range, כדי ליצור עותק של מקטע של הרצף הזה. דוגמה:
oneToSeven = range(1, 8)
oneToThree = oneToSeven [:4]
בדוגמה זו מופעל האופרטור [ ] על oneToSeven, רצף המספרים השלמים החל מ-1 עד 7 (כולל). הפעלתו יוצרת רצף חדש. רצף זה מכיל את כל המספרים ב-oneToSeven החל מהמספר באינדקס 0 עד המספר באינדקס 3 (כולל).
לדיון נוסף בשימוש באופרטור [ ] ליצירת מקטע רצף ראו נספח ג’.
(9) מיון – הפונקציה sorted
פייתון מציעה יותר מפונקציה אחת למיון רצפים. כאן נתמקד במיון רצפים באמצעות הפונקציה sorted. פונקציה זו מקבלת רצף נתון ויוצרת רשימה חדשה המכילה את הערכים ברצף הנתון כשהם ממוינים. הנה דוגמה ראשונה – הפעלת הפונקציה sorted על רשימה של מספרים:
סverses = [15, 9, 18]
sortedVerses = sorted(verses)
print(sortedVerses)
>>>
[9, 15, 18]
כאן העברנו לפונקציה sorted את הרשימה verses. ברשימה זו יש שלושה מספרים שלמים. הפונקציה לא שינתה את הרשימה verses, אלא יצרה רשימה חדשה, המתקבלת ממיון המספרים ברשימה verses, החזירה רשימה זו, והרשימה החדשה הוצבה במשתנה sortedVerses.
באמצעות הפונקציה sorted אפשר למיין גם רשימה של מחרוזות. המיון הוא לפי סדר המילון, ואותיות אנגליות ב-upper case (אותיות “גדולות”) קודמות לאותיות ב-lower case (אותיות “קטנות”). הנה דוגמה לשימוש בפונקציה sorted למיון רשימה המכילה קיצורים של שמות ספרי מקרא (Gen. הוא קיצור של Genesis (בראשית), Ex. הוא קיצור של Exodus (שמות) וכו’):
bookNames = [‘Gen.’, ‘Ex.’, ‘Lev.’]
sortedBookNames = sorted(bookNames)
print(sortedBookNames)
>>>
[‘Ex.’, ‘Gen.’, ‘Lev.’]
מה מחזירה הפונקציה sorted כאשר היא מקבלת מחרוזת? עיינו בקטע קוד זה ובפלט של הרצתו:
letters = ‘aBbA’
sortedLetters = sorted(letters)
print(sortedLetters)
>>>
[‘A’, ‘B’, ‘a’, ‘b’]
הערכים במחרוזת (ברצף) letters הם התווים המרכיבים אותה. הפונקציה sorted יוצרת רשימה המכילה את התווים האלה כשהם ממוינים, ומחזירה רשימה זו.
ברירת המחדל של הפונקציה sorted היא שהמיון יהיה בסדר לא-יורד, כלומר שכל ערך ברשימה יהיה קטן יותר מהערך הבא אחריו או שווה לו. נוכל לקבוע כי המיון יהיה בסדר לא-עולה, כלומר שכל ערך ברשימה יהיה גדול יותר מהערך הבא אחריו או שווה לו. נעשה זאת באמצעות הנחת ביטוי זה לפני הסוגר העגול הסוגר בזימון הפונקציה
reverse = True
במינוח רשמי: הביטוי מעביר את הארגומנט True לפרמטר reverse של הפונקציה. דיון בהעברת ארגומנטים לפרמטרים של פונקציה מובא בפרק העשירי.
הנה דוגמה לקביעת סדר המיון בזימון הפונקציה sorted:
bookNames = [‘Gen.’, ‘Ex.’, ‘Lev.’]
sortedBookNames = sorted(bookNames, reverse = True)
print(sortedBookNames)
>>>
[‘Lev.’, ‘Gen.’, ‘Ex.’]
שימו לב כי בתוך הסוגריים העגולים המופיעים לצד שם הפונקציה sorted, הנחנו פסיק בין הרשימה שיש למיין (bookNames) לבין הביטוי הקובע את אופן המיון.
אי אפשר למיין רצף שיש בו הן מחרוזות הן מספרים, וככלל אי אפשר למיין רצף שאין מוגדרת בו השוואה בין כל ערך וערך בו. לדוגמה זימון הפונקציה sorted כאן יוליך לשגיאת TypeError:
verses = [15, 9, 18, ‘not a verse number’]
sortedVerses = sorted(verses, reverse = True)
print(sortedVerses)
>>>
sortedVerses = sorted(verses, reverse = True)
TypeError: ‘<‘ not supported between instances of ‘int’ and ‘str’
השגיאה כאן נוצרת בשל אי היכולת להשוות בין המחרוזות למספרים ברשימה המתקבלת בתור ארגומנט לפונקציה sorted.
אפשר למיין רשימות שהערכים בהם הם רשימות (ובניסוח כללי: רצפים שהערכים בהם הם רצפים). דוגמה:
verses = [[‘Gen.’, 16, [15]],
[‘Gen.’, 15, [2, 4, 8]],
[‘Ex.’, 1, [9, 13]] ]
sortedVerses = sorted(verses)
print(sortedVerses)
>>>
[[‘Ex.’, 1, [9, 13]], [‘Gen.’, 15, [2, 4, 8]], [‘Gen.’, 16, [15]]]
המיון כאן מתחיל במיון ראשי, ומיון זה נעשה לפי הערכים הראשונים ברשימות הפנימיות. בדוגמה זו הערכים האלה הם שמות ספרים. אם המיון הראשי הוא על שני ערכים שווים הפונקציה sorted תמיין מיון משני, לפי הערכים השניים ברשימות. כאן ברשימה המקורית verses הופיעו שתי רשימות פנימיות שהערך הראשון בהן שווה, ‘Gen’. לכן התבצע מיון משני לפי מספר הפרק. ברשימה המקורית הרשימה הפנימית שמספר הפרק בה הוא 16 באה לפני הרשימה הפנימית שמספר הפרק בה הוא 15. ברשימה הממוינת הסדר של שתי הרשימות הפנימיות הללו הוא הפוך.
(10) סיכום
בנקודה זו מסתיים דיון המבוא ברצפים. דיון זה התמקד בפעולות המשותפות לרצפים. נמנו עם פעולות אלו יצירת עותקים של ערכים ברצפים ומקטעים ברצפים, סריקת רצפים, בדיקות בנוגע לתכנם של רצפים (האם הם ריקים, האם ערך מסוים מופיע בהם, וכו’), ויצירה של רצפים חדשים לפי רצפים קיימים (באמצעות האופרטורים + ו-*, מיון ועוד). פעולה אחת ברצפים התבלטה בהעדרה מהדיון: והיא שינוי תכנו של רצף נתון. האפשר לשנות תווים שמחרוזת מורכבת מהם? האפשר לשנות ערכים שרשימה מורכבת מהם? בשאלות אלו נעסוק בהרחבה בשני הפרקים הבאים, אגב הדגשת הקווים המייחדים מחרוזות מרשימות ורשימות ממחרוזות.